ジャパンサーチからSPARQLでデータ取得

ジャパンサーチとは
ジャパンサーチは,様々な分野のデジタルアーカイブと連携することで, 日本が保有するコンテンツを横断的に検索することができるポータルサイトのことです(現在はベータ版が公開). コンテンツには,作品名,分類,品質形状,時代世紀,所蔵者などのメタデータ付与されており, 地方活性化,教育研究など様々な目的で活用することが可能となっています. 2019年10月現在においては,連携データベース数は50,また, 登録されているメタデータ件数(コンテンツ数)は17,959,770となっており, 今後も登録数は増加していくと考えられます.
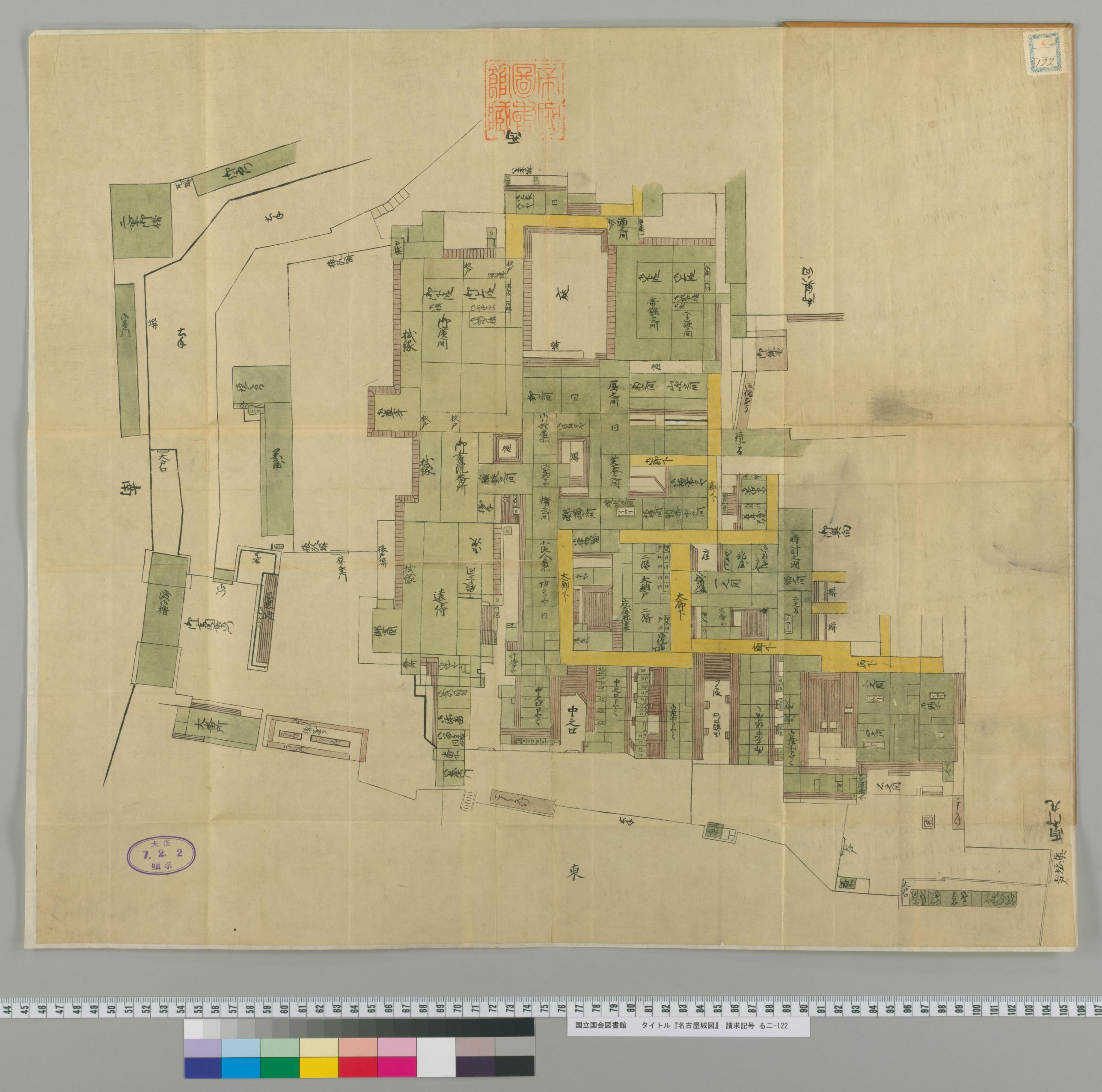
それでは,「名古屋城図」をキーワードに検索してみましょう. すると,国立国会図書館デジタルコレクションに所属される 名古屋城図がヒットします. このデジタル化された地図は パブリックドメイン であり,著作権による制限を受けず,自由に利用することができます. また,メタデータとして,下記に示すような情報が提供されます(一部のみを掲載).
| 項目 | 値 |
|---|---|
| 名称/タイトル | 名古屋城図[1] |
| 名称/タイトルヨミ | ナゴヤジョウズ |
| 資料種別 | 和古書 |
| 著作権情報 | インターネット公開(保護期間満了) |
| 件名 | 城郭/尾張国/名古屋 |
| 提供者のURL | http://dl.ndl.go.jp/info:ndljp/pid/2589695 |
| サムネイル画像URL | http://dl.ndl.go.jp/titleThumb/info:ndljp/pid/2589695 |
これらのレコード(メタデータ)を取得するには下記の2通りの方法があります.
簡易Web API は,登録されているレコードを検索するための簡易的な機能です. プログラミングの必要はなく,ブラウザで指定する URL に一工夫するだけで検索が可能です. 一方,SPARQL APIは,問い合わせ言語であるSPARQL(スパークル)を利用して, 様々な条件を指定してレコードを取得する機能です.
簡易Web API を体験してみよう!
簡易Web APIは,下記URLに引数(条件)を与えてアクセスすることで, 条件を満たしたレコードをJSON形式で取得可能な仕組みになっています.
https://jpsearch.go.jp/api/item/search/jps-cross?
取得されるJSON形式のデータをそのまま人間が理解するのは困難です. そこで,weBinko JSON Visualizationなどの可視化ツールを利用すると良いです.
キーワードで検索
キーワードで検索するには,URLの最後にkeyword=(キーワード)を指定します.
例えば,名古屋城図を検索する場合は,下記のURLにアクセスします.
https://jpsearch.go.jp/api/item/search/jps-cross?keyword=名古屋城図
取得件数の制限
このままだと検索結果が多すぎて分かりにくいので,取得件数を制限することにします.
取得件数を制限するするには,size=(件数)を指定します.
例えば,2件のレコードを取得する場合は,下記のURLにアクセスします.
https://jpsearch.go.jp/api/item/search/jps-cross?keyword=名古屋城図&size=2
人物を指定した検索
レコードに関連する人物の名前を指定して検索することもできます.
人物を指定するには,q-contributor=(人物の名前)を指定します.
例えば,豊臣秀吉に関連するするレコードを取得する場合は,下記のURLにアクセスします.
https://jpsearch.go.jp/api/item/search/jps-cross?q-contributor=豊臣秀吉&size=2
場所を指定した検索
レコードに関連する場所の名前を指定して検索することもできます.
場所を指定するには,q-loc=(場所の名前)を指定します.
例えば,名古屋に関連するするレコードを取得する場合は,下記のURLにアクセスします.
https://jpsearch.go.jp/api/item/search/jps-cross?q-loc=名古屋&size=2
SPARQL API を体験してみよう!
SPARQL(スパークル)は, W3C によって標準化された問い合わせ言語です. データベースに詳しい方はSQLと名前が似ていることに気づくのではないでしょうか. 実際,SPARQLの記述ルールはSQLにとてもよく似ています.
例えば,ジャパンサーチから古書・古文書を検索するには,下記のように記述します. SELECTやWHEREなど馴染みのある単語が並んでいますね(詳細は次章で解説).
SELECT ?url WHERE{
?url rdf:type type:古書・古文書.
}
PythonやRubyなど主要なプログラミング言語では, SPARQLを利用するためのライブラリが提供されており, 比較的簡単に導入が可能です. また,ジャパンサーチ以外にも,SPARQLが利用可能なサービスが存在しています. その多くは,LOD(Linked Open Data)と呼ばれる, ウェブ上でデータを公開・共有するための仕組みであり, その検索にSPARQLが採用されています.
ここでは,JavaScriptを利用して,ジャパンサーチにSPARQLで問い合わせをしてみましょう. ソースはGitHubで公開していますので,各自ダウンロード(またはクローン)してください. GitHubに詳しくない場合は, Download ZIP をクリックし,ダウンロードしたZIPファイルを展開すると良いです.
それでは,index.htmlをブラウザで開いてみてください. これは,SPARQLで取得したデータを表形式に整形し表示したものです(jQueryなどのライブラリを利用していますが詳細は割愛). SPARQLを書き換えれば,この結果も変わることになります(ブラウザのリロードが必要なことに注意すること).
次に,sparql.jsをエディタ(Atomなど)で開いてください.
このファイルには,6つのSPARQLの例が記述されており,
それぞれ,sparql1,spqrql2などの変数に代入されています.
また,myqueryという変数に,上記のいずれかを代入することで,
対象のSPARQLを実行するという仕組みになっています.
初期状態では,sparql1が実行されます.
myqueryへの代入を変更すると,表示結果も変わることを確認してください.
var sparql1 = `
SELECT ?url WHERE{
?url rdf:type type:古書・古文書.
}
`;
var myquery = sparql1
古書・古文書で検索
それでは,具体例を見ていきましょう.
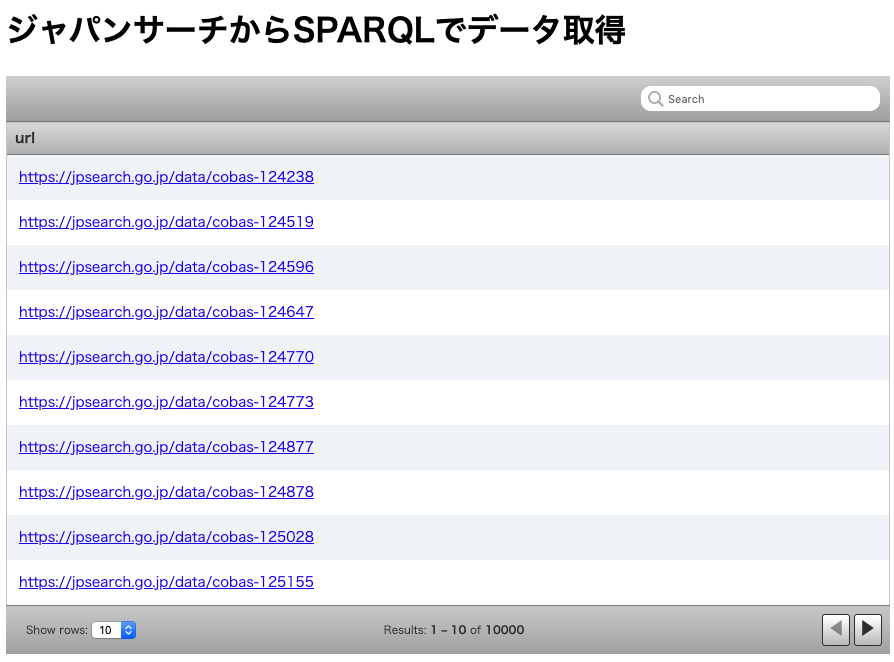
1番目のSPARQLは下記のように記述されています.
SELECTの後にある?urlは取得するデータ,
また,WHEREに続くブロックは検索条件を表しています.
SELECT ?url WHERE{
?url rdf:type type:古書・古文書.
}
検索条件は RDF(Resource Description Framework) と呼ばれる枠組みで表現することになっています. これは,RDFトリプルとも呼ばれ,主語,述語, 目的語 を組み合わせて表現します.
上記の例では,主語は?url,述語はrdf:type,目的語はtype:古書・古文書に一致します.
まず,?urlは,ジャパンサーチのコンテンツそのものであり,そのコンテンツのメタデータが記載されたURL(URL)を表します.
次に,rdf:typeは,プロパティと呼ばれ,コンテンツの基本区分を表しています(基本区分の一覧はコチラ).
最後に,type:古書・古文書は,プロパティに対する値であり,ジャパンサーチによって事前に定義されています.
つまり,このSPARCLは「基本区分が古書・古文書であるコンテンツのURL」の検索を意味しています.
プロパティは,rdf:typeに加え,コンテンツを識別する名前であるrdfs:label,
コンテンツの時間に関する情報を表すschema:temporal,
コンテンツの位置に関する情報を表すschema:spatialなどがあります.
詳しくは公式の利活用スキーマ解説を参照してください.
| プロパティ | 意味 | 値の例 |
|---|---|---|
| rdf:type | コンテンツの基本区分 | type:古書・古文書 |
| rdfs:label | コンテンツを識別するラベル | “名古屋城図” |
| schema:temporal | コンテンツの時間に関する情報 | time:1900 |
| schema:spatial | コンテンツの位置に関する情報 | place:愛知 |
| schema:about | コンテンツの主題・分類・ジャンル | keyword:城郭_尾張国_名古屋 |
検索された結果の最初のレコードを確認してみましょう. 基本区分が古書・古文書となっていることがわかります.
ラベルの表示
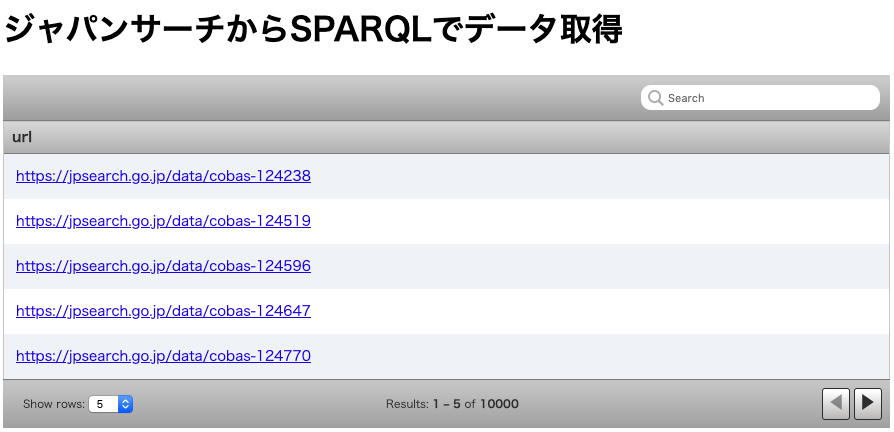
2番目のSPARQLは下記のように記述されています.
SELECTに ?label が追加され,
また,WHEREにはコンテンツのラベルを表すrdfs:labelを用いた条件が追加されています.
SELECT ?url ?label WHERE {
?url rdf:type type:古書・古文書.
?url rdfs:label ?label.
}
この条件は,主語は?url,述語はrdfs:label,目的語は?labelに一致します.
実は,この目的語の?labelは値ではなく,変数を意味しています(接頭語として?を付けると変数になる).
変数は特定の値ではなく,条件を満たす全て が該当します.
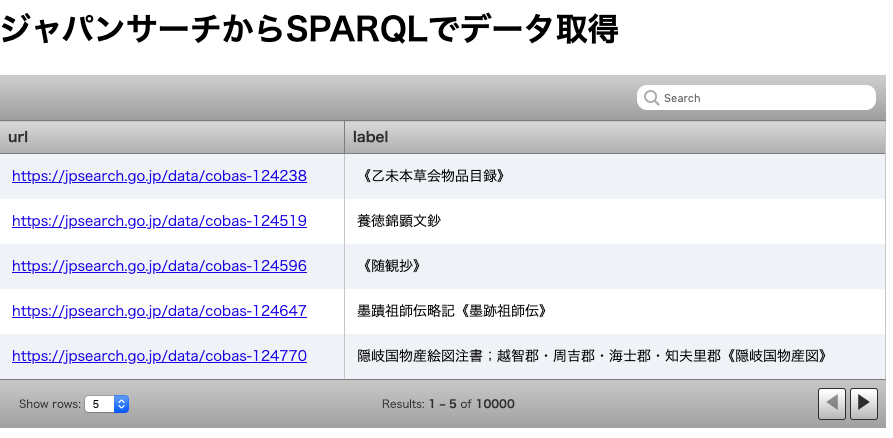
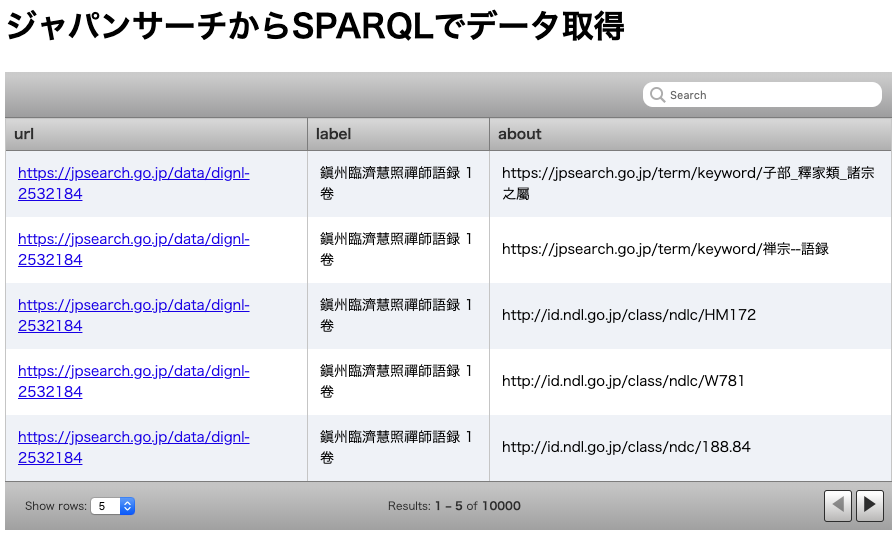
主題・分類・ジャンルの表示
3番目のSPARQLは下記のように記述されています.
SELECTに ?about が追加され,
また,WHEREにはコンテンツの主題・分類・ジャンルを表すschema:aboutを用いた条件が追加されています.
SELECT ?url ?label ?about WHERE {
?url rdf:type type:古書・古文書;
rdfs:label ?label;
schema:about ?about.
}
この条件は,述語はschema:about,目的語は?aboutに一致しますが,主語が見当たりません.
実は,これは主語を省略した記述方法です.
条件を複数列挙するとき,主語が共通の場合は,条件の最後に;を付けることで,次の条件からは主語を省略できます.
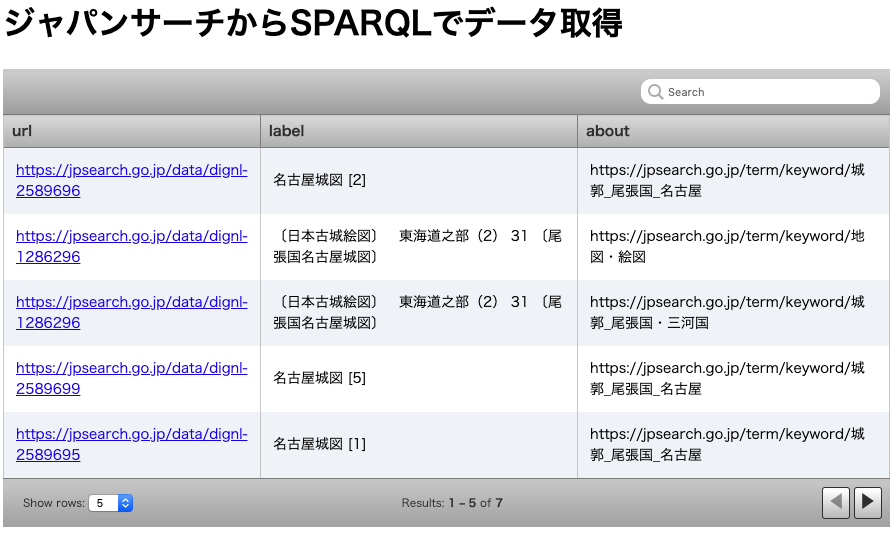
検索結果をフィルタリング
4番目のSPARQLは下記のように記述されています. SELECTには変更はありませんが, WHEREにはFILTER式 を用いた条件が追加されています.
SELECT ?url ?label ?about WHERE {
?url rdf:type type:古書・古文書;
rdfs:label ?label;
schema:about ?about.
FILTER CONTAINS(?label, "名古屋城図")
}
この FILTER式 は検索結果にフィルタをかけて,特定のレコードのみを抽出する機能があります.
ここでは,?labelに 名古屋城図 という文字列を含むレコードのみを抽出しています.
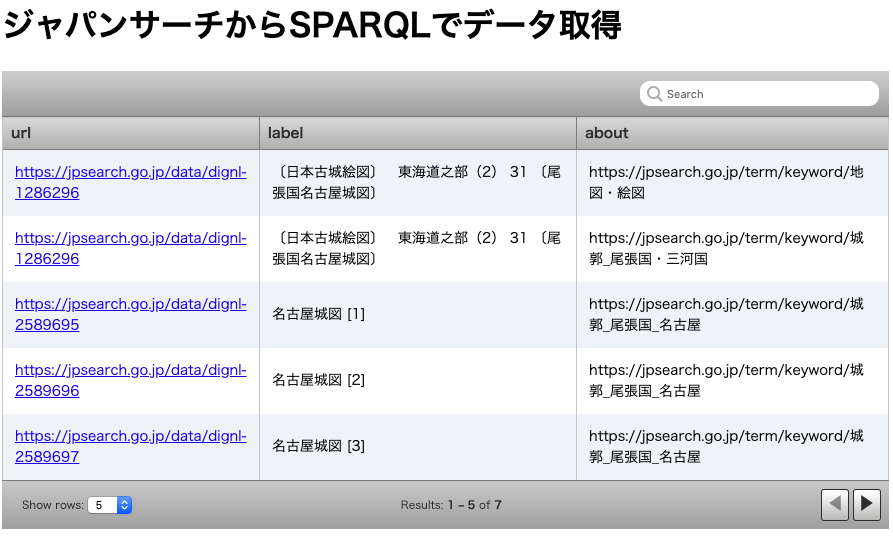
検索結果で並べ替え
5番目のSPARQLは下記のように記述されています. WHEREの後に ORDER BY が追加されています.
SELECT ?url ?label ?about WHERE {
?url rdf:type type:古書・古文書;
rdfs:label ?label;
schema:about ?about.
FILTER CONTAINS(?label, "名古屋城図")
}
ORDER BY ?label
この ORDER BYは,指定した変数の値を昇順で並び替えを行います. 降順にする場合は ORDER BY DESC と記述します. ここでは,ラベルの昇順で並び替えてることがわかります.
検索結果数の制限
6番目のSPARQLは下記のように記述されています. WHEREの後に LIMIT が追加されています.
SELECT ?url ?label ?about WHERE {
?url rdf:type type:古書・古文書;
rdfs:label ?label;
schema:about ?about.
FILTER CONTAINS(?label, "名古屋城図")
}
LIMIT 3
この LIMITは,検索結果数を制限するときに用います. ここでは,3件のレコードのみを取得しています.

最後に
ここでは,デジタルアーカイブの横断検索が可能なジャパンサーチに注目し, 簡易Web APIとSPARQL APIを利用して,コンテンツのメタデータを検索する方法を紹介しました. 日本は世界でも有数の文化資材を保有する国の一つです. これらコンテンツを有効活用することで,日本の魅力はさらに向上し, 我々の生活はより文化的に豊かになることが予想されます. ここで学んだ知識・技術を活用しすることで, 世界を席巻するようなアプリやサービスが登場することを期待しています.