オープンデータを利用した人口データの可視化

オープンデータとは
平成24年,日本において公共データの活用促進を目的として電子行政オープンデータ戦略が策定されました. この戦略では,「公共データ活用の推進」「公共データ活用のための環境整備」が具体的な施策とされており, これらの施策の鍵となるのがオープンデータです.
オープンデータは下記に従うことを条件としています.
- 機械判読に適したデータ形式
- 二次利用が可能な利用ルールで公開
つまり,行政(地方自治体)が保持している統計データや施設データなどを, 誰もが再利用や再頒布ができることを条件に,コンピュータに扱いやすい形式で公開されたデータをオープンデータと呼びます. 企業や個人のデータでも上記に従えばオープンデータですが,ここでは,行政のデータにターゲットを絞ります(オープンガバメントデータと呼ぶこともあります). 一般に,再利用や再頒布が可能なソフトウェアのことはオープンソースと呼ばれることも合わせて覚えておきましょう.
ここで,ポイントとなるのは,「機械判読に適したデータとは何か?」ということです. 一般に小規模のデータを管理するときには,エクセル を採用することが多いです. 文化情報学部では,1年後期に開講されている「コンピュータと情報 Ⅱ」において,エクセルの使い方を学習します. たしかに,エクセルは,デザイン(書式)や関数など様々な機能を提供しており,人間にとってはとても便利なソフトウェアです. しかし,これらのデータをコンピュータで処理しようとするとき,これらの機能が却って冗長となり,コンピュータによる判読が難しい状況が起こります.
具体例をみてみましょう. まずは,エクセル形式(.xlsx)で表現された日進市の人口のデータ(jinkou.xlsx)です. タイトル部分に太字,表部分に罫線などのデザイン(書式)が設定されていることが分かります. これらは,エクセルを利用している人間が見るためのデザインであり,データの本質ではありません. また,エクセル形式の実態は,XMLや画像などで構成されるZIPファイルであり, エクセルなどの専用のソフトウェアでしか開くことはできません.
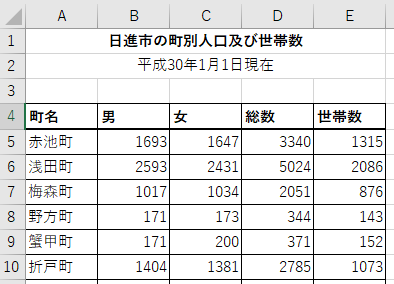
次に,CSV形式(.csv)で表現された日進市の人口のデータ(jinkou.csv)です. CSVは「しーえすぶい」と読み,オープンデータで頻繁に採用されるデータ形式です. データが「,(カンマ)」で区切られて表現されるだけで,エクセルのようなデザイン(書式)は含みません. このため,一般的なエディタ(メモ帳)でも開くことができます(エクセルでも開けます). エクセル形式に比べると,人間にとっては理解しにくいですが,コンピュータの判読には優れています.
町名,男,女,総数,世帯数
赤池町,1693,1647,3340,1315
浅田町,2593,2431,5024,2086
梅森町,1017,1034,2051,876
野方町,171,173,344,143
蟹甲町,171,200,371,152
折戸町,1404,1381,2785,1073
今回の授業では,日進市のオープンデータポータルサイトで公開されている CSV形式のデータをプログラミング言語のPythonで可視化することを目的とします.
公開されているオープンデータ
オープンデータはウェブで公開されるのが一般的であり, 総務省が運用するData.go.jpがオープンデータのカタログサイトとして知られています. このサイトでは,国土交通省,経済産業省などの組織別のデータセット,また,行財政や観光などのトピックに関するデータ・セットが提供されています. 例えば,観光 というキーワードで検索すると,「平成28年度 国際経済調査事業報告書」,「平成28年度 商店街インバウンド・空き店舗実態調査」などのデータセットがヒットします(平成30年2月28日現在). しかし,残念ながら,これらの多くはPDF形式での提供であり,「機械判読に適したデータ」ではありません. 現状では,まだまだオープンデータの整備は不十分と言えるでしょう.
この他,内閣府のまち・ひと・しごと創生本部が提供している地域経済分析システム(RESAS)が注目されています. RESAS(りーさす)は,総務省が提供している統計情報 e-Statのオープンデータなどを可視化するためのシステムです. 地方自治体の現状や課題を発見することを目的としており,情報を直感的にわかりやすく見える化することができます. 例えば,2015年の愛知県名古屋市の 人口マップ を下記のように可視化することができます. マウスで各市区町村をホバーすると人口が表示され,名古屋市千種区は164,696人であることが分かります. また,人口推移や人口ピラミッドなどのグラフも簡単に描画することができます. このようにデータを可視化して,分かりやすく伝えることも,オープンデータの活用に必要な要素です.
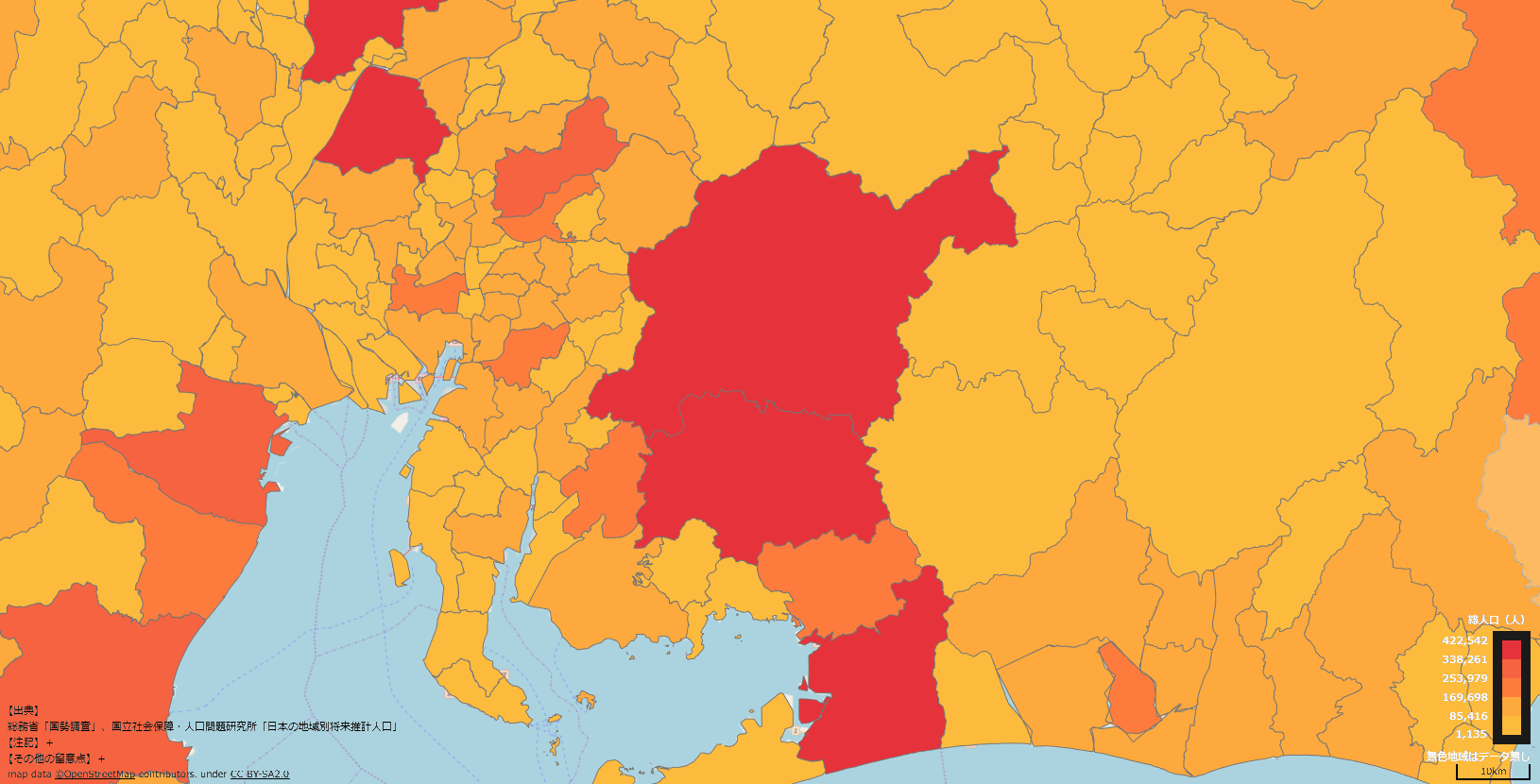
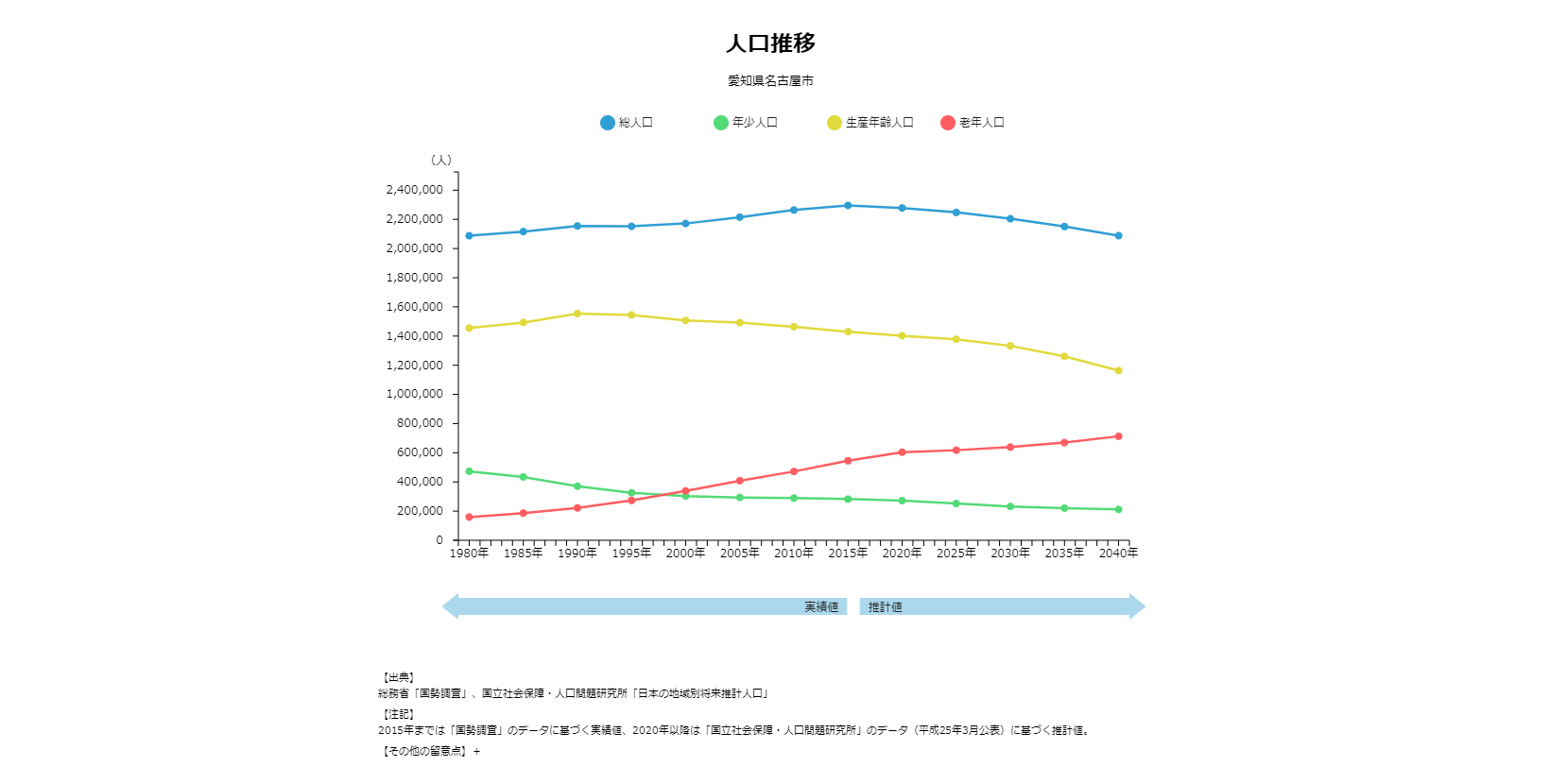
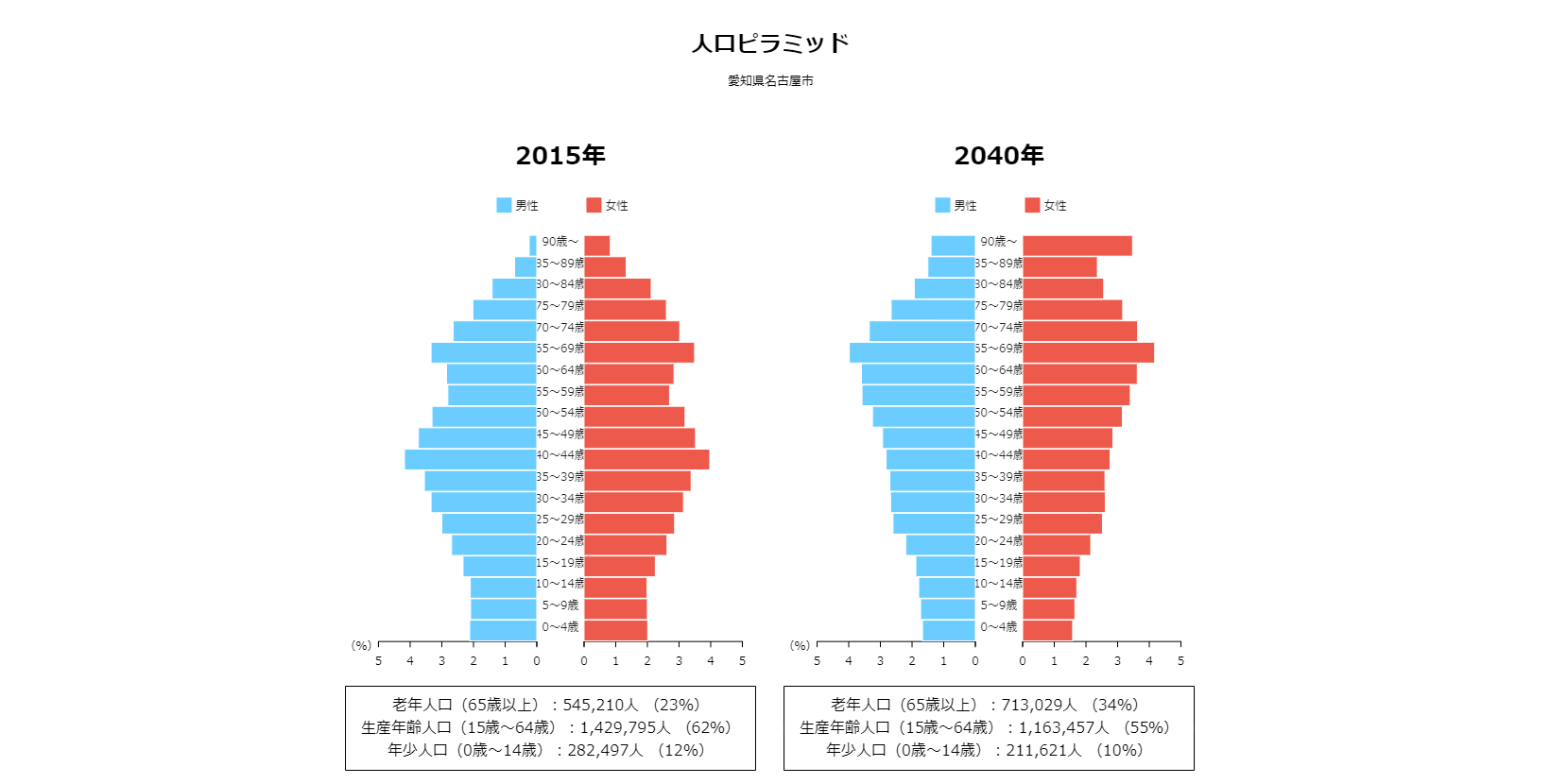
愛知県下においては,オープンデータに関する取り組みを精力的に進める自治体の一つに 日進市 があります.日進市のウェブサイトでは,オープンデータポータルサイトを開設しており, 住民向け情報(暮らしの情報),事業者向け情報,行政活動情報,観光情報の区分に分けてオープンデータを公開しています. また,平成28年度には,瀬戸市,尾張旭市,豊明市,日進市,みよし市,長久手市,東郷町の7市町で 「7市町オープンデータ検討会」を組織し,連携してオープンデータの整備を始めています. これまでに,7市町が共通のフォーマットで,子育て支援施設,教育機関などのデータを各自治体のウェブサイトで公開しています. 今回は日進市のオープンデータポータルサイトで公開されている 人口データ を加工して利用します. 下記のリンクをダウンロードして確認してください.
Google Colaboratory
データの分析・可視化は Python の開発プラットフォームの一つであるGoogle Colaboratoryを利用します.
本来は Python の基本から習得が必要ですが,この授業ではデータの分析・可視化の流れを体験することを目的とし,コードをコピー&ペーストしながら作業を進めます. コピーするには「Ctrl + c(「コントロールキー」を押しながら「c」)」,ペーストするには「Ctrl + v(「コントロールキー」を押しながら「v」)」を利用します. コードの詳細を理解する必要はありませんが,何を目的としてコーディングしているかは把握しながら進めましょう.
オープンデータの可視化
それでは,Google Colaboratoryを利用して,オープンデータの可視化とグラフの作成に挑戦しましょう.
ノートブックの作成
まずは,ノートブックを作成します. ノートブックの名前は chapter1.ipynb に設定します.

データの分析・可視化に利用するライブラリを導入します.
最初にグラフ描画ライブラリのmatplotlibを
日本語化するjapanize-matploblibを pipコマンド でインストールします.
先頭に「!」を付けることに注意してください.
!pip install japanize-matplotlib
上記のmatplotlibに加えて,
データ解析ライブラリであるpandasをインポートします.
pyplotの別名としてplt,pandasの別名としてpdを指定しています.
import matplotlib.pyplot as plt
import japanize_matplotlib
import pandas as pd
データフレーム(pandas)
pandasを利用して,
CSV形式のオープンデータ(nisshin_population.csv)を読み込みます.
読み込まれたデータは データフレーム と呼ばれる形式で保持されます.
ここでは,dfという変数(データを記録する箱)にデータフレームが代入されます.
データフレームは2次元の表であり,エクセルのワークシートと同じような概念です.
行番号として$0,1,\cdots,100$,列ラベルとして年齢,合計,男 などが設定されています.
# nisshin_population.csv
url = "https://mukai-lab.info/classes/seminar_fundamental_areas/csv/nisshin_population.csv"
# データフレームの生成
df = pd.read_csv(url)
# HTMLで表示(=display(df))
df
データの抽出
列ラベルを指定して,データを抽出するには,df[列ラベル]と記述します.
df["男"]
複数の列ラベルを指定して,データを抽出するには,df[列ラベル1,列ラベル2,...]と記述します.
df[["年齢","男","女"]]
行番号を指定して,データを抽出するには,df[先頭の行番号:後尾の行番号]と記述します.
このとき抽出されるのは,後尾の行番号は含まず,一つ前のデータまでが含まれることに注意してください.
df[18:22]
条件を設定してデータを抽出することができます.
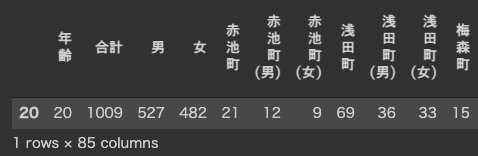
例えば,年齢が20のデータを抽出するには下記のように記述します.
ここで,==は左辺と右辺が一致することを意味します.
df[df["年齢"] == 20]
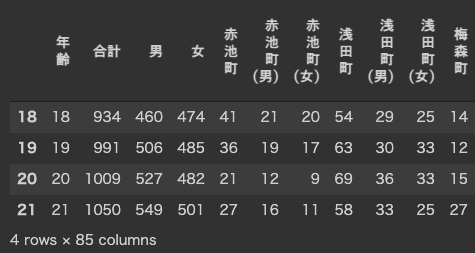
複数の条件を設定してデータを抽出することができます.
例えば,年齢が18以上,21以下であるデータを抽出するには下記のように記述します.
ここで,>=は「左辺は右辺以上である」,<=は「左辺は右辺以下である」ことを意味します.
df[(df["年齢"] >= 18) & (df["年齢"] <= 21)]
グラフの作成
matplotlibを利用して,データをグラフで可視化します.
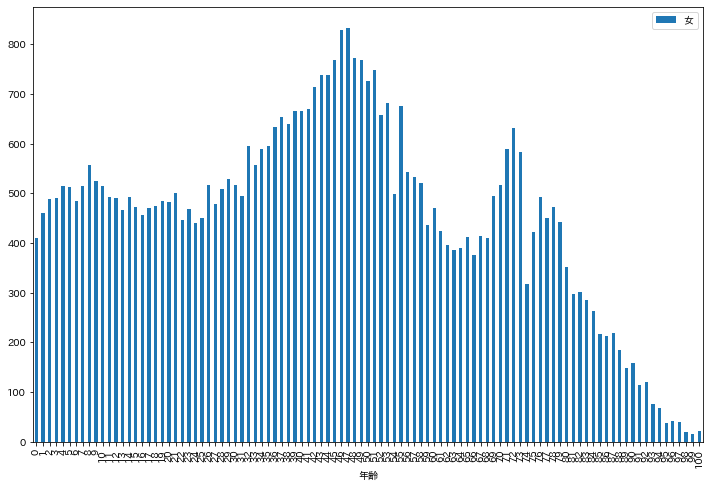
棒グラフを作成するにはdf.plot.bar()を用います.
ここで,xはX軸,yはY軸,figsizeはグラフの大きさを意味します.
df.plot.bar(x="年齢", y=["女"], figsize=(12, 8))
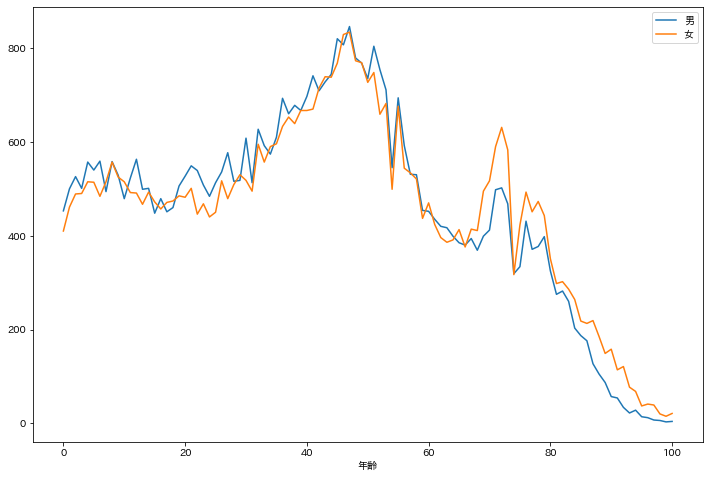
折れ線グラフを作成するにはdf.plot.line()を用います.
ここでは,Y軸に男と女のデータを指定しています.
df.plot.line(x="年齢", y=["男", "女"], figsize=(12, 8))
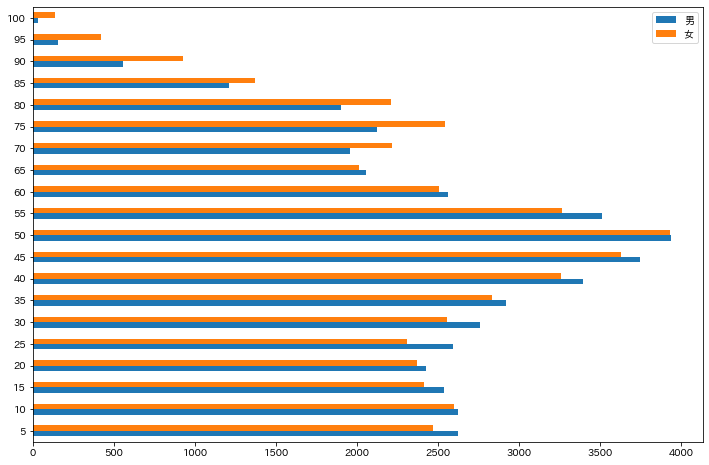
横棒グラフを作成するにはdf.plot.barh()を用います.
ここでは,5歳間隔で人口を集計します.
df.rolling()を用いると指定した区間のデータをまとめて対象にすることができ,
sum()によって対象の区間の合計を算出します.
また,列番号に[::5]と指定することで,5列おきにデータが抽出されます.
df_population = df[["男", "女"]].rolling(5).sum() # 5歳分を合計
df_population = df_population[::5] # 5歳間隔で抽出
df_population[1:].plot.barh(figsize=(12, 8)) # 0歳を除く
本日のノートブックは下記URLで確認できます.
課題
Google Colaboratoryで作成した chapter1.ipynb を保存し, ノートブック(.ipynb) をダウンロードして提出しなさい. 提出の前に必ず下記の設定を行うこと.
- ノートブックの設定で「セルの出力を除外する」のチェックを外す
- ノートブックの変更内容を保存して固定