 えむラボ
えむラボ主成分分析
主成分分析(Principal Component Analysis: PCA) は,複数の変数を合成して,少数の変数を生成することで,次元圧縮・削減することを目的とします. 合成された変数は 主成分 と呼ばれ,寄与率(全体に占める分散の割合) が大きい順に,第1主成分,第2主成分と呼ばれます.
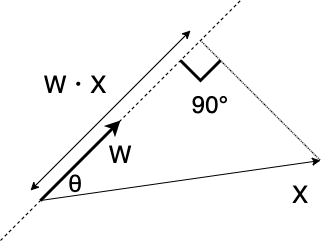
変数$X = (x_1, x_2, \cdots, x_n)$を合成した主成分を考えます. ここで,変数の重みを表す主成分負荷量(Loadings)を$W=(w_1, w_2, \cdots, w_n)$と表すことにします. ただし,主成分負荷量を表すベクトル$W$の長さは$|W|=1$とします. このとき,主成分の軸上の値となる主成分得点(Score)は,$X$と$W$の内積で表されます.
$$ W \cdot X = w_1 \cdot x_1 + w_2 \cdot x_2 + \cdots + w_n \cdot x_n $$
$$ |W| = \sqrt{w_1^2 + w_2^2 + \cdots + w_n^2} = 1 $$
また,$X$と$W$の内積は,ベクトルの成す角$\theta$を用いて,次のように表現することもできます. つまり,主成分得点は,ベクトル$W$を延長した軸に対して,ベクトル$X$を射影したときの長さと一致します.
$$ W \cdot X = |W| \cdot |X| \cdot \cos{\theta} = |X| \cdot \cos{\theta} $$
例えば,変数$x_1$を身長,変数$x_2$を体重とした主成分分析を考えます. 次の表はe-Statで公開されている5歳から14歳までの男性の身長,座高,体重の平均です.
| 年齢 | 身長$x_1$ | 体重$x_2$ |
|---|---|---|
| 5 | 110.7 | 19.0 |
| 6 | 116.7 | 21.5 |
| 7 | 122.6 | 24.1 |
| 8 | 128.3 | 27.2 |
| 9 | 133.6 | 30.6 |
| 10 | 138.9 | 34.2 |
| 11 | 145.1 | 38.4 |
| 12 | 152.5 | 44.2 |
| 13 | 159.7 | 49.1 |
| 14 | 165.2 | 54.3 |
このとき,主成分得点は次の式で表されます.
$$ W \cdot X = w_1 \cdot x_1 + w_2 \cdot x_2 $$
$$ |W| = \sqrt{w_1^2 + w_2^2} = 1 $$
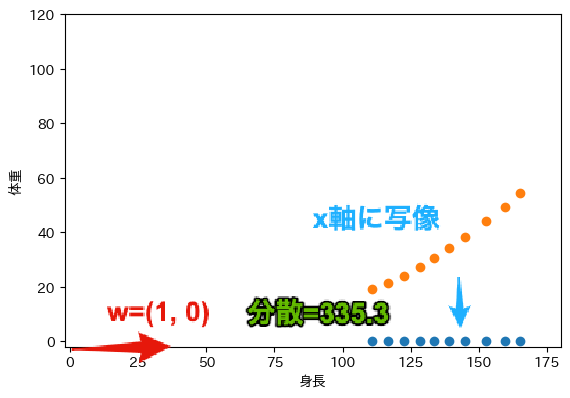
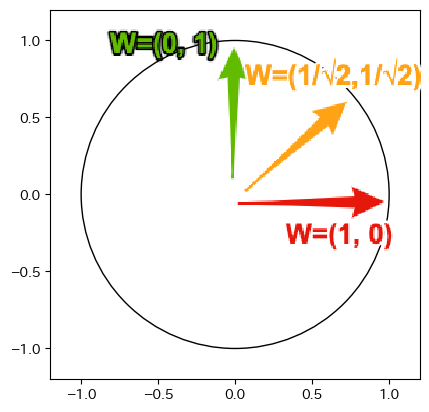
最初に$W=(1, 0)$を考えます. このとき,$W \cdot X = x_1$となり,主成分得点は身長$x_1$を表すことになります. これは,次の図に示すように,X軸への射影と一致します. また,主成分得点の分散は335.3です.
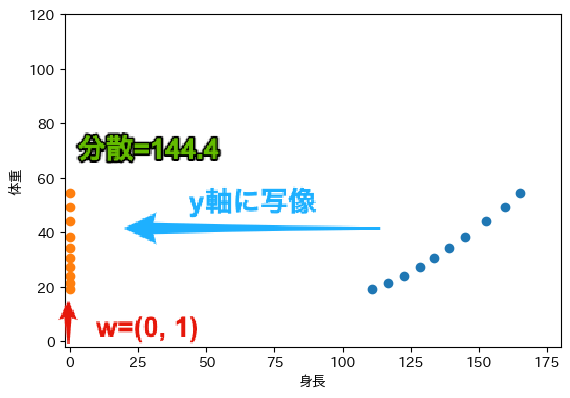
次に$W=(0, 1)$を考えます. このとき,$W \cdot X = x_2$となり,主成分得点は体重$x_2$を表すことになります. これは,次の図に示すように,Y軸への射影と一致します. また,主成分得点の分散は144.4です.
次に$W=(1/\sqrt{2}, 1/\sqrt{2})$を考えます. このとき,$W \cdot X = \frac{x_1 + x_2}{\sqrt{2}}$となり,主成分得点は身長$x_1$と体重$x_2$を合成した値となります. これは,次の図に示すように,ベクトル$W$を延長した軸への射影と一致します. また,主成分得点の分散は458.7です.
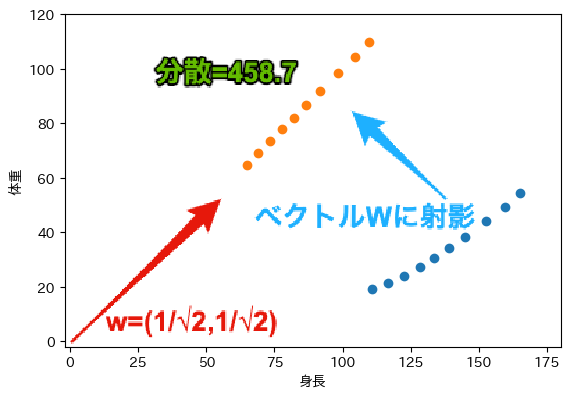
上記の3パターンの分散を比較すると,$W=(1/\sqrt{2}, 1/\sqrt{2})$の分散が最も大きく, サンプル間の特徴が明確となるため,主成分として適していることになります. $|W|=1$であることから,ベクトル$W$は原点$(0,0)$を中心とした半径$1$の円を表すことになり, この円周上で最も分散が大きくなる$W$を探すことが,主成分分析の目的となります.
データセット
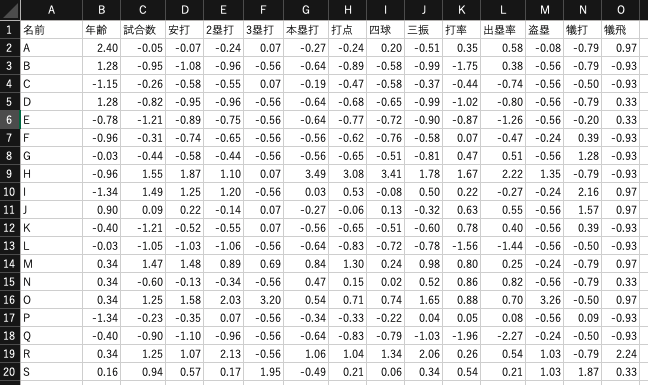
ここでは,次のCSV形式のデータセットを利用します. 下記のURLからファイルをダウンロードしてください. ある野球チームに所属する19人の打撃に関するデータであり, 年齢,試合数,安打などの14項目で構成されています(名前はアルファベットで表記).
名前,年齢,試合数,安打,2塁打,3塁打,本塁打,打点,四球,三振,打率,出塁率,盗塁,犠打,犠飛
A,40,81,55,8,1,5,22,28,28,0.248,0.336,3,0,3
B,34,47,3,1,0,0,0,6,7,0.136,0.321,0,0,0
C,21,73,29,5,1,6,14,6,34,0.206,0.238,0,1,0
D,34,52,10,1,0,0,7,4,7,0.175,0.234,0,0,2
E,23,37,13,3,0,0,4,2,11,0.183,0.2,0,2,2
Excelで主成分分析
Excelを利用して主成分分析を試してみましょう. ダウンロードしたファイルをExcelで開いてください. ここでは,年齢や試合数など14項目の変数($x_1,x_2,\cdots,x_{14}$)から,第1主成分を求めます.
標準化
行$22$に平均,行$23$に標準偏差を求めます.
平均はaverage関数,標準偏差はstdev関数を利用します.
例えば,$B21$は=AVERAGE(B2:B20),$B22$は=STDEV(B2:B20)と入力します.

新しいシートを作成し,standarize関数を利用して,標準化したデータを入力します.
標準化とは,平均を0,標準偏差を1に変換する操作を意味し,先に算出した平均と標準偏差を用います.
例えば,$B2$は=STANDARDIZE(Sheet1!B2,Sheet1!B$21,Sheet1!B$22)と入力します.
主成分負荷量と主成分得点
行$22$に主成分負荷量$W$を入力します. 初期値は,$w_1=1$とし,$w_2,\cdots,w_{14}$は$0$に設定します. このとき,$|W|=1$となります.

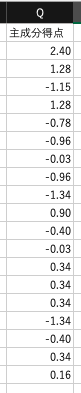
列$Q$に主成分得点$W \cdot X$を入力します.
内積はsumproduct関数を用いると簡単に計算できます.
例えば,$Q2$は=SUMPRODUCT($B$22:$O$22,B2:O2)と入力します.
目的関数と制約条件
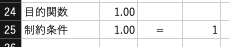
$B24$に目的関数,$B25$に成約条件を入力します.
目的関数は主成分得点$W \cdot X$の分散であり,=VAR(Q2:Q20)で算出します.
成約条件は$|W|=1$であり,=SQRT(SUMPRODUCT(B22:O22,B22:O22))で算出します.
ソルバー
データ・タブからソルバーを選択します. ソルバーのパラメータに,目的セル(目的関数),変数セル(変数)を設定します. 解決方法はGRG非線形を選択市,解決ボタンをクリックします.
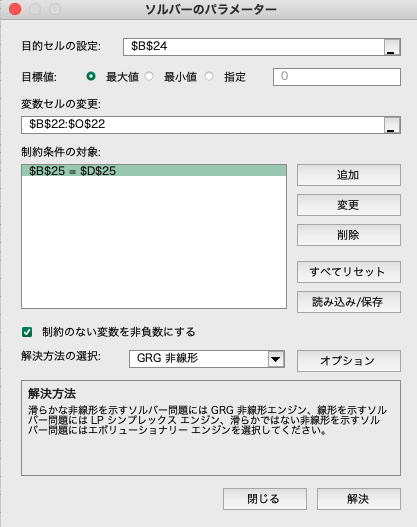
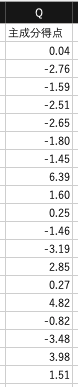
この結果,主成分負荷量$W$と,主成分得点$W \cdot X$は次のようになりました.

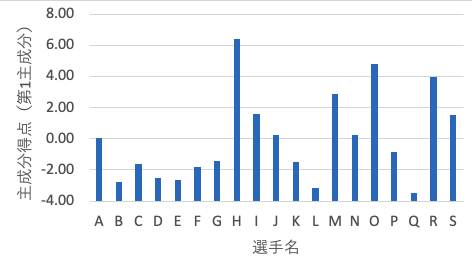
グラフの作成
主成分得点を棒グラフで表してみます. 選手Hが6.39で最も大きな得点となりました. 次いで選手Oが4.82で2番目に大きな得点です. 主成分負荷量は,安打,打点,三振が約0.33,試合数,2塁打が約0.32と大きな値を示しています. 一方,犠打,年齢は約0であり,第1主成分に寄与していません. このことから,第1主成分は,打席に立つ機会が多い 中心選手 を表していると考えられます.
Pythonで主成分分析
Pythonを利用して,主成分分析を試してみましょう. ここでは,年齢や試合数など14項目の変数($x_1,x_2,\cdots,x_{14}$)から, 第1主成分と第2主成分を求めます.
Jupyter Labを起動して,Python 3のノートブックを開きます. ノートブックの名前は chapter14.ipynb とします.
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
データセットの読込
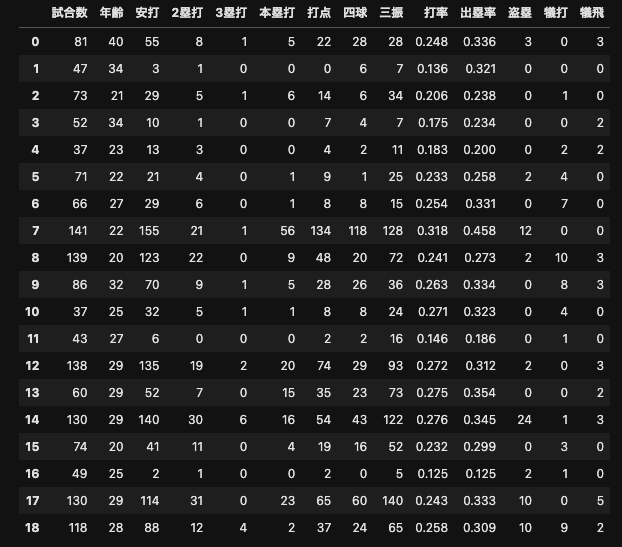
read_csv関数でデータセットを読み込みます.
また,対象とする14項目の変数($x_1,x_2,\cdots,x_{14}$)を抽出します.
df = pd.read_csv("../dataset/dataset13.csv")
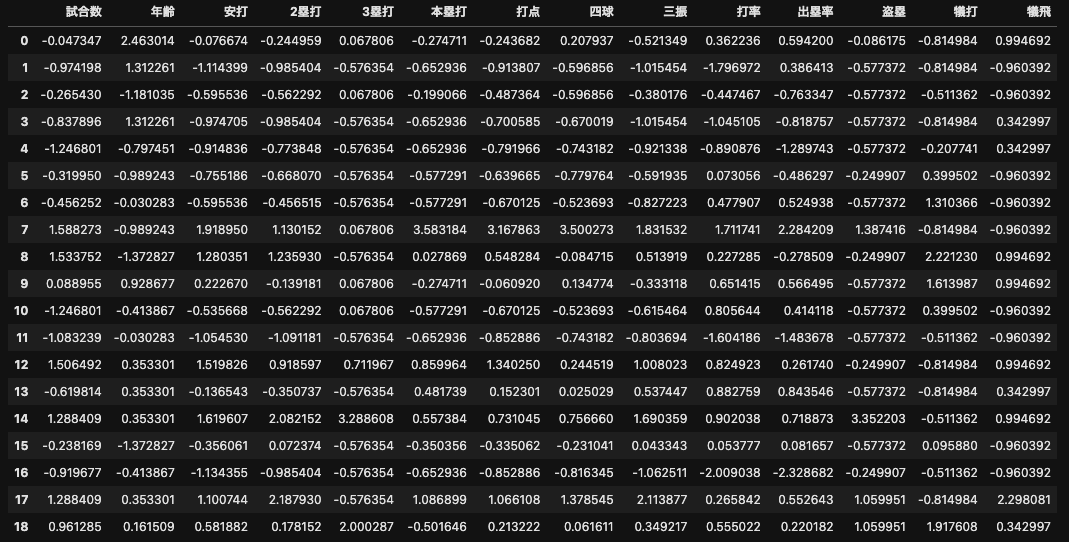
target_columns = ["試合数", "年齢", "安打", "2塁打", "3塁打", "本塁打", "打点", "四球", "三振", "打率", "出塁率", "盗塁", "犠打", "犠飛"]
target_df = df[target_columns]
display(target_df)
標準化
StandardScalerを利用して,平均$0$,標準偏差$1$に標準化します.
# 標準化
scaler = StandardScaler()
data = scaler.fit_transform(target_df)
# 標準化したデータでデータフレームを再構築
target_df = pd.DataFrame(data)
target_df.columns = target_columns
display(target_df)
主成分分析
PCAを利用して,主成分分析を実行します.
n_components=2を指定して,第2主成分まで算出します.
# 主成分分析
pca = PCA(n_components=2)
pca.fit(target_df)
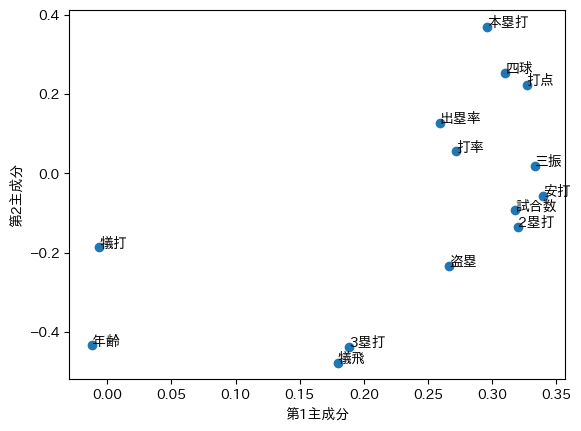
主成分負荷量$W$を散布図で可視化します. 横軸は第1主成分,縦軸は第2主成分の主成分負荷量を表しています. 第1主成分に関しては,Excelの算出結果と同様に,安打,打点,三振が大きな値を示しています. また,犠打・年齢は約0となっている点も同じです. このことから,第1主成分は,打席に立つ機会が多い 中心選手 を表していると考えられます. 一方で,第2主成分に関しては,本塁打,四球,打点が大きな値を示しています. また,犠飛,三塁打,年齢,盗塁,犠打が低い値を示しています. このことから,第2主成分は,長打力 を表していると考えられます.
comp1 = pca.components_[0] # 第1主成分
comp2 = pca.components_[1] # 第2主成分
plt.scatter(comp1, comp2, label=target_columns)
for x, y, column in zip(comp1, comp2, target_columns):
plt.text(x, y, column)
plt.xlabel("第1主成分")
plt.ylabel("第2主成分")
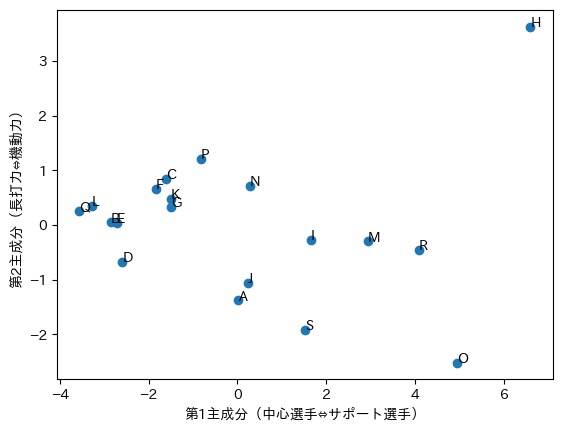
主成分得点$W \cdot X$を散布図で可視化します. 第1主成分は,選手H,O,Rの得点が高く,チームの中心選手であることがわかります. また,第2主成分は,選手Hは得点が高いことから長打力のある選手,選手Oは得点が低いことから機動力のある選手であることがわかります.
# 主成分得点(第1主成分)
score_x = list((target_df * pca.components_[0]).sum(axis=1))
# 主成分得点(第2主成分)
score_y = list((target_df * pca.components_[1]).sum(axis=1))
plt.scatter(score_x, score_y)
for x, y, name in zip(score_x, score_y, df["名前"]):
plt.text(x, y, name)
plt.xlabel("第1主成分(中心選手⇔サポート選手)")
plt.ylabel("第2主成分(長打力⇔機動力)")
寄与率
第1主成分と第2主成分の寄与率を確認します. 第1主成分の寄与率は58.3%であり,全体の約6割の情報を占めていることがわかります. また,第2主成分の寄与率は11.5%であり,約1割を占めていることがわかります. 合わせて約7割となっており,大部分の情報は第1主成分と第2主成分で表現できていると言えそうです.
# 寄与率
pca.explained_variance_ratio_
array([0.58329665, 0.11521758])
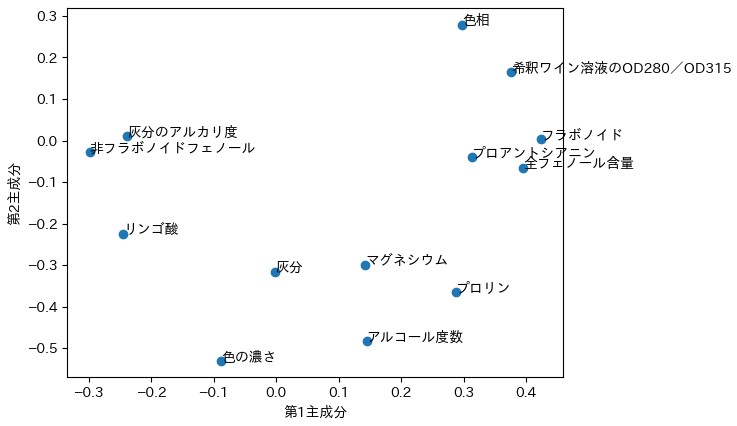
課題
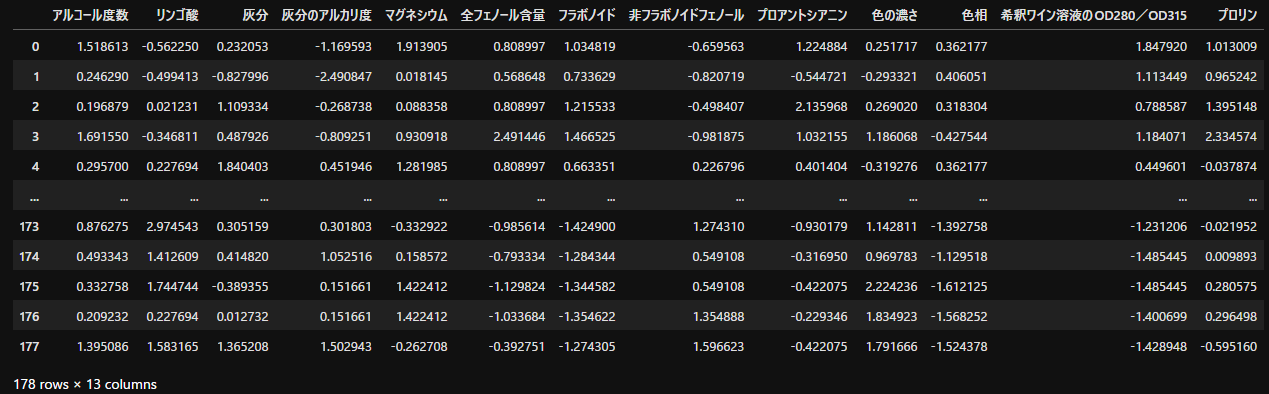
ワインのデータを主成分分析して,第1主成分と第2主成分を求めなさい. 各データはアルコール度数,りんご酸など13の特徴量で構成されている.
from sklearn.datasets import load_wine
data = load_wine()
wine_columns = [
"アルコール度数",
"リンゴ酸",
"灰分",
"灰分のアルカリ度",
"マグネシウム",
"全フェノール含量",
"フラボノイド",
"非フラボノイドフェノール",
"プロアントシアニン",
"色の濃さ",
"色相",
"希釈ワイン溶液のOD280/OD315",
"プロリン"
]
wine_df = pd.DataFrame(data.data)
wine_df.columns = wine_columns
display(wine_df)
Jupyter Labで作成したノートブックを保存し,ダウンロードして提出してください. ノートブックをダウンロードするには,メニューから Download を選択します. ノートブックのファイル名は chapter14.ipynb としてください.