 えむラボ
えむラボ
Kaggleとは
Kaggle はGoogle傘下のAlphabet社が手掛ける予測モデリングのコンペティションです. 「タイタニック号の予測」など様々なコンペティションが提供されており, なかには多額の賞金や景品が懸けられているコンペティションもあります. 科学者やエンジニアなど,様々な分野の人が登録しており, 機械学習やデータサイエンスなどのアプローチで問題を解くことに挑戦しています. ここでは,Kaggleの基本的な使い方を学習し,「タイタニック号の予測」に挑戦してみます. 下記のURLからKaggleにアクセスし,大学のGmailアカウントでログインしてください.
ノートブックの作成
Colabにアクセスし,新規にノートブックを作成してください. ノートブックのタイトルは chapter14 とします. また,下記のライブラリを導入しておいてください.
!pip install japanize-matplotlib
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import japanize_matplotlib
from sklearn import tree
from sklearn.tree import plot_tree
タイタニック号の生存予測
「タイタニック号の生存予測(Titanic - Machine Learning from Disaster)」に挑戦してみましょう. このコンペの目的は,タイタニック号の乗客の属性(性別,年齢など)から,生存を予測することです. Kaggleの導入に最適なコンペとされています.
https://www.kaggle.com/c/titanic
データ
上述したように,タイタニック号の乗客の属性(性別,年齢など)から,生存を予測します. ここでは,次に挙げる属性を利用します.
- PassengerId(乗客ID)
- Survived(1:生存,0:死亡)
- Pclass(チケットクラス 1:1st,2:2nd,3:3rd)
- Sex(性別 male:男性 female:女性)
- Age(年齢)
- SibSp(同乗している兄弟/配偶者の数)
- Parch(同乗している親/子供の数)
- Fare(料金)
- Embarked(出港地)
予測に用いるデータは次の3種類です. Kaggleからダウンロードしておきましょう. 決定木などの機械学習モデルを train.csv で学習し,学習したモデルで test.csv の分類結果を予測します. 最後に gender_submission.csv のフォーマットに従って,test.csvの分類結果を submission.csv にまとめて提出します. gender_submission.csv の初期値は,男性は死亡(0),女性は生存(1)になっています.
- train.csv(訓練用データ)
- test.csv(テスト用データ)
- gender_submission.csv(提出用データ)
| PassengerId | Survived | Pclass | Sex | Age | SibSp | Parch | Fare | Embarked |
|---|---|---|---|---|---|---|---|---|
| 1 | 0 | 3 | male | 22 | 1 | 0 | 7.25 | S |
| 2 | 1 | 1 | female | 38 | 1 | 0 | 71.2833 | C |
| 3 | 1 | 3 | female | 26 | 0 | 0 | 7.925 | S |
決定木を利用した予測
データの読込
ダウンロードした train.csv ,test.csv ,gender_submission.csv をColabにアップロードします.
ファイル選択をクリックし,上記の3つのファイルを選択します.
アップロードされたファイルは,Colabの/content/に保存されます.
# データのアップロード
from google.colab import files
uploaded = files.upload()
for fn in uploaded.keys():
print('User uploaded file "{name}" with length {length} bytes'.format(
name=fn, length=len(uploaded[fn])))
train.csv をデータフレームとして読み込みます.
head()で最初の5つのレコードを表示させています.
train_df = pd.read_csv("train.csv")
display(train_df.head())

同様に,test.csv をデータフレームとして読み込みます. test.csvにはSurvivedの属性が含まれていないことに注意してください.
test_df = pd.read_csv("test.csv")
display(test_df.head())

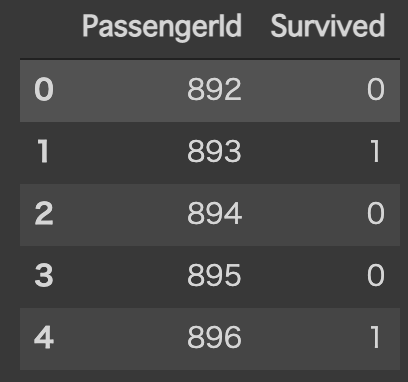
最後に,gender_submission.csv をデータフレームとして読み込みます. このファイルはKaggleに結果を提出する際に用いるフォーマットであり,PassengerIdとSurvivedの2列で構成されます. また,これらのPassengerIdは, test.csv に含まれるPassengerIdと一致します.
submission_df = pd.read_csv("gender_submission.csv")
display(submission_df.head())
フィルタ&ダミー変数
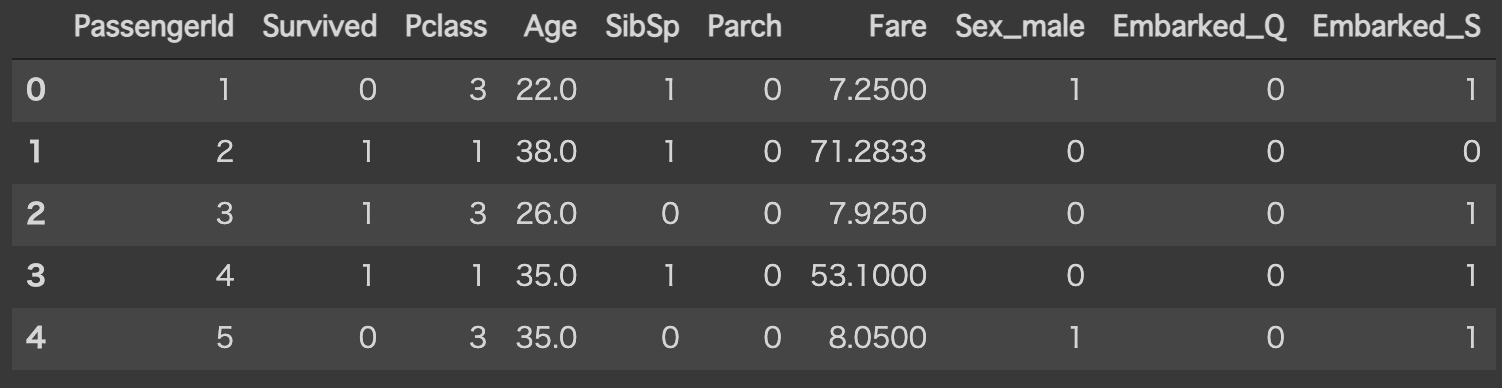
分類に用いる属性のみをフィルタし,質的変数はダミー変数に変換します.
質的変数はSex(性別)とEmbarked(出港地)の2種類です.
Sex(性別)の場合は,0:女性,1:男性に変換されます.
また,Embarked(出港地)は,下記の表のように変換されます.
加えて,空値(Nan)は平均値に置き換えています.
| Embarked | Embarked_Q | Embarked_S |
|---|---|---|
| Q | 1 | 0 |
| S | 0 | 1 |
| C | 0 | 0 |
train_df = train_df[["PassengerId", "Survived", "Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]]
train_df = pd.get_dummies(train_df, drop_first=True)
train_df = train_df.fillna(train_df.mean())
display(train_df.head())
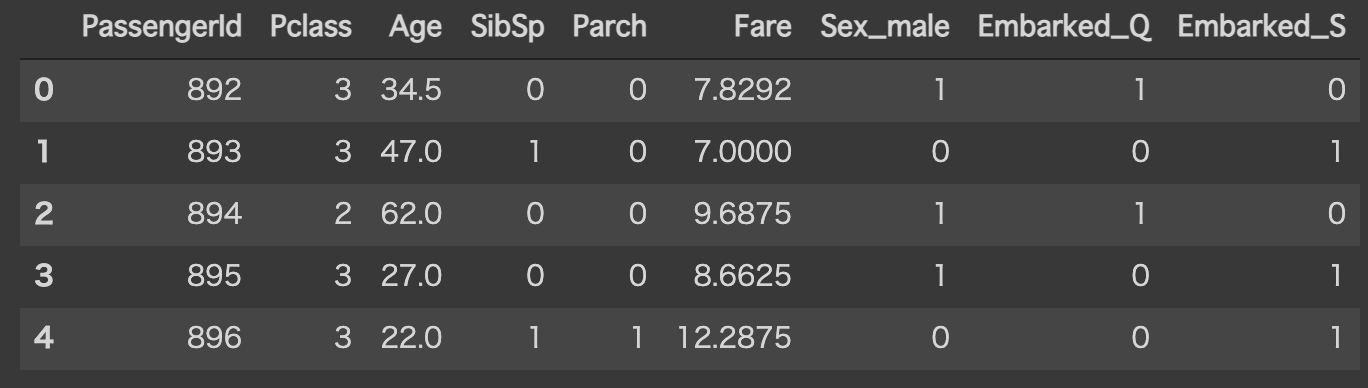
test_df = test_df[["PassengerId", "Pclass", "Sex", "Age", "SibSp", "Parch", "Fare", "Embarked"]]
test_df = pd.get_dummies(test_df, drop_first=True)
test_df = test_df.fillna(test_df.mean())
display(test_df.head())
訓練データ
train.csv から,PassengerIdとSurvivedを削除し,決定木の訓練データとして用います. PassengerIdは乗客に対するユニークなIDであり分類には用いません(オーバーフィッティングしてしまう).
data_df = train_df[["Pclass", "Age", "SibSp", "Parch", "Fare", "Sex_male", "Embarked_Q", "Embarked_S"]]
display(data_df.head())
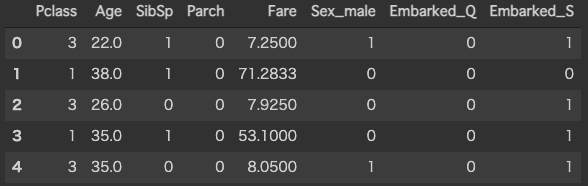
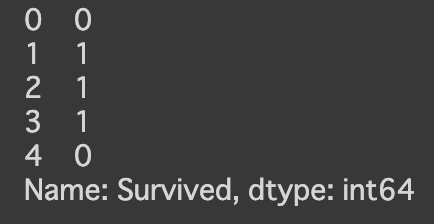
訓練データの正解ラベルであるSurvivedを抽出しておきます. 1列だけ抽出したデータは,データフレームではなく,シリーズ(Series)になることに注意してください.
target_df = train_df["Survived"]
display(target_df.head())
決定木の学習
上記の訓練データと正解ラベルを用いて決定木を学習します. 訓練データに対する正解率は82.27%でした.
# 決定木で学習
t = tree.DecisionTreeClassifier(criterion="entropy", max_depth=3, random_state=0)
t = t.fit(data_df, target_df)
score = t.score(data_df, target_df)
print(f"Score: {score}")
Score: 0.8226711560044894
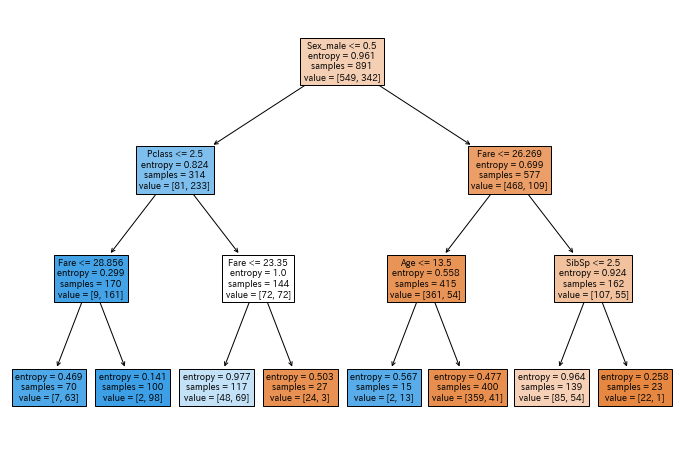
決定木を可視化してみます. ルートノードはSex(性別)であり,右の部分木は男性,左の部分木は女性に分けられることがわかります.
# 決定木を可視化
plt.figure(figsize=(12, 8))
plot_tree(t, feature_names=data_df.columns, filled=True)
評価データに対する分類
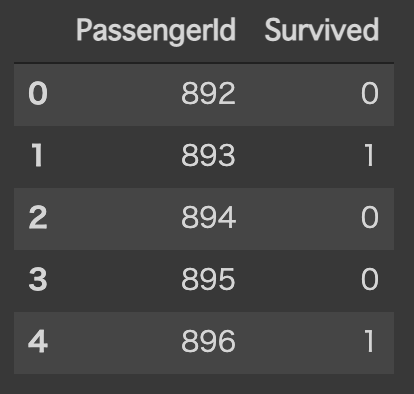
学習した決定木を用いて,評価データを分類します.
例えば,PassengerId=892は「死亡(0)」,PassengerId=893は「生存(1)」に分類されています.
この結果を,submission_df に,古いデータを削除してから追加します.
# テストデータからPassengerIdを除く
test_df = test_df[["Pclass", "Age", "SibSp", "Parch", "Fare", "Sex_male", "Embarked_Q", "Embarked_S"]]
display(test_df.head())
# テストデータで分類
survived = t.predict(test_df)
submission_df = submission_df.drop("Survived", axis=1)
submission_df = submission_df.assign(Survived=survived)
display(submission_df.head())
最後に submission_df をCSVファイル(submission.csv)として保存します. 保存したファイルはColabからダウンロードしておきます.
# 結果を保存
submission_df.to_csv("submission.csv", index=False)
ファイル(分類結果)の提出
ダウンロードした submission.csv をKaggleに提出します. 提出の際は,ファイルの簡単な説明を記述します.
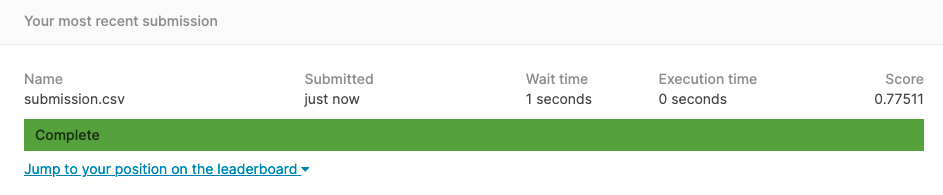
提出されたファイルは,Kaggleで自動的にチェックされ,正解率が算出されます. テストデータに対する正解率は77.51%でした.
課題
自由にコードを変更し,評価データに対する正解率を改善してください. 課題を完成させたら,chapter14.ipynb を保存し, 共有用のリンク と ノートブック(.ipynb) をダウンロードして提出してください. このとき,必ず事前に下記の設定を行ってから提出してください.
- ノートブックの設定で「セルの出力を除外する」のチェックを外す
- ノートブックの変更内容を保存して固定
- 共有設定で「学校法人椙山女学園大学」を「閲覧者」に設定