えむラボ
えむラボ
ノートブックの作成
Jupyter Notebook を起動し,新規にノートブックを作成してください. ノートブックのタイトルは AI-3 とします. ノートブックの作成方法は第1回の資料を参照してください.
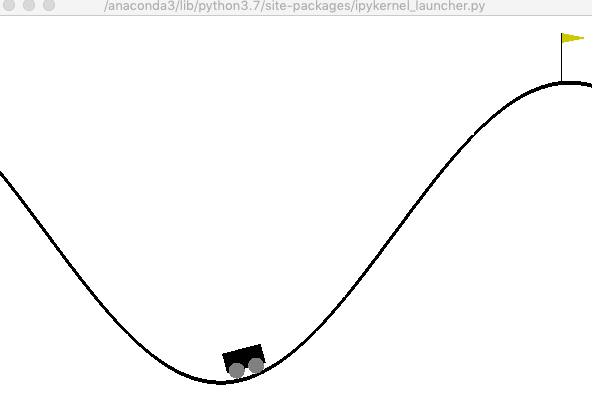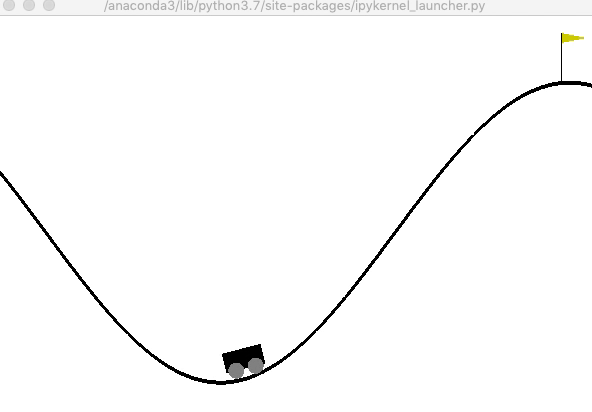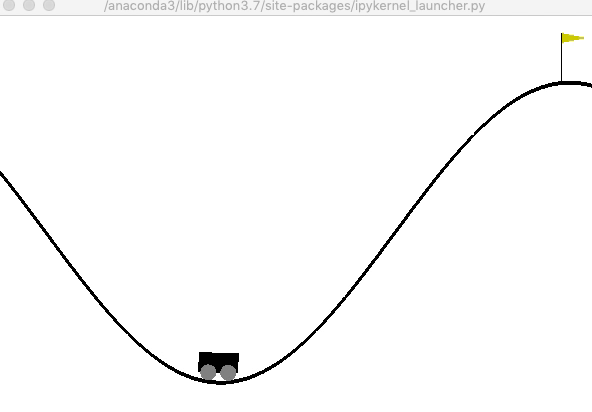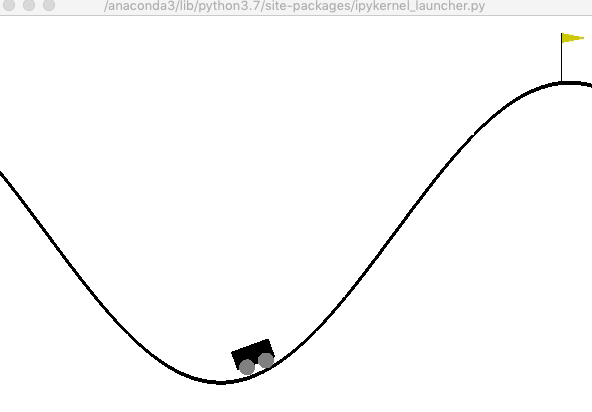
山登りゲーム(MountainCar)
山登りゲームは,車両を山の上の旗がある場所まで移動させることが目的です(旗の位置は0.5). ユーザは,下記の状態を観測することが出来ます.
- 車両の位置(-1.2 〜 0.6)
- 車両の速度(-0.07 〜 0.07)
また,ユーザは,車両に対し,下記のいずれかの行動をとることが出来ます.
- 後方に加速(0)
- 加速なし(1)
- 前方に加速(2)
下記の条件を満たしたとき,ゲームは失敗となります.
- 旗に到達できず200ステップが経過する
今回は,この山登りゲームをQ学習で解いてみましょう. 基本的には前回のバランスゲームの実装方法と同じです.
[学習前]
[学習後]
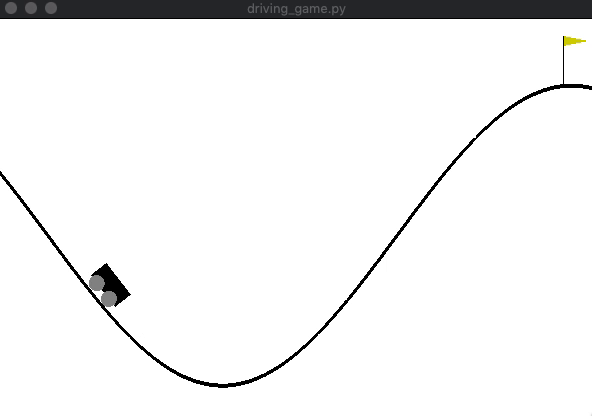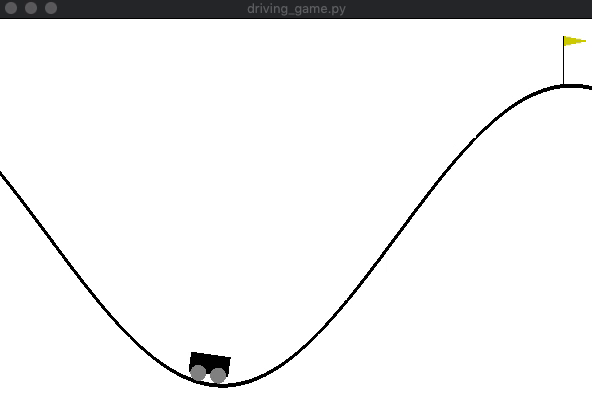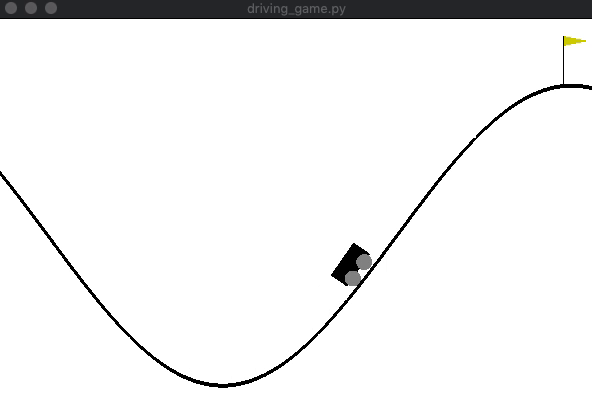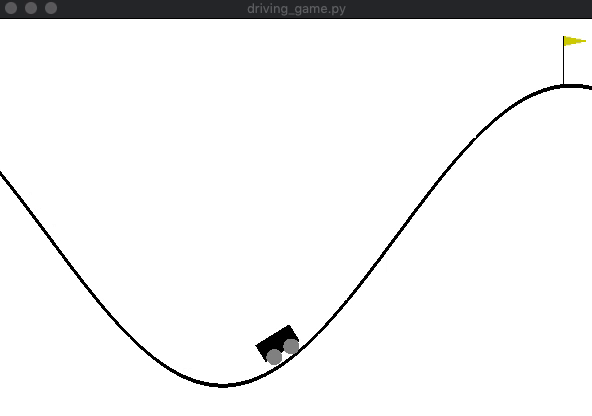
山登りゲームの実装
まずは必要なライブラリの導入と,山登りゲーム(MountainCar-v0)の初期化をします.
import gym
import numpy as np
env = gym.make('MountainCar-v0') # 環境の初期化
次に,200ステップに限定して,ランダムな行動選択を行なった結果を確認しましょう. 車両は谷底をウロウロするだけで,山を登ることはありません.
env.reset() # 環境のリセット
for i in range(200):
action = env.action_space.sample() # ランダムに行動選択
observation, reward, done, info = env.step(action)
print("Step {}".format(i+1))
print("状態: {}".format(observation))
print("終了判定: {}".format(done))
env.render() # 環境の描画
Q学習の実装
Qテーブルの作成
最初に 価値$Q(s,a)$ を記録しておくQテーブル(辞書型)を作成します. 前回のバランスゲームと全く同じです.
q_table = {} # Qテーブル
# Q値の設定
def setQ(state, action, value):
q_table[(state, action)] = value
# Q値の取得
def getQ(state, action):
# テーブルに状態が存在しないとき
if not(state, action) in q_table:
q_table[(state, action)] = 0
return q_table[(state, action)]
状態の離散化
次に状態の離散化を行います. 山登りゲームでは,車両の位置,車両の速度の2つの状態を 連続値 で取得します. しかし,このままではQテーブルに記録できないため,区間を定め 離散値 に変換します. バランスゲームでは6区間でしたが,今回は40区間に分割することにします.
BIN_NUMBER = 40 # 離散値の数
# 離散値の範囲
bins = []
bins.append(np.linspace(-1.2, 0.6, BIN_NUMBER)) # 車両の位置
bins.append(np.linspace(-0.07, 0.07, BIN_NUMBER)) # 車両の速度
# 観測データを状態(離散値)に変換
def digitize(observation):
state = []
state.append(np.digitize(observation[0], bins[0]))
state.append(np.digitize(observation[1], bins[1]))
return tuple(state)
どのように離散値に変換されるか確認してみましょう. この例では,$(17,20)$ -> $(17,20)$ -> $(17,19)$と状態が変化していることが確認できます.
env.reset() # 環境のリセット
for i in range(3):
action = env.action_space.sample() # ランダムに行動選択
observation, reward, done, info = env.step(action)
print(observation)
print(digitize(observation))
[-4.21336289e-01 2.46770426e-04]
(17, 20)
[-0.42184451 -0.00050822]
(17, 20)
[-0.4241041 -0.00225958]
(17, 19)
報酬と更新式
報酬をgetReward関数で定義します.
200ステップ以内に旗に到達できれば$r=200$を与えます.
一方,旗に到達できない場合は常に$r=-1$のペナルティを与えます.
# 報酬の取得
def getReward(step, done):
if done:
if step < 200:
reward = 200 # 目標ステップ以内に旗に到達
else:
reward = -1
else:
reward = -1
return reward
Qテーブルの更新式をupdateQTable関数で定義します.
このとき,学習率$\alpha=0.1$,割引率$\gamma=0.9$とします.
ここで,Qテーブルのキーは状態$s$と行動$a$のペアとなることに注意してください.
alpha = 0.1 # 学習率
gamma = 0.9 # 割引率
# Q値の更新
def updateQTable(state, action, next_state, reward):
max_value = max(getQ(next_state, 0), getQ(next_state, 1), getQ(next_state, 2))
value = (1 - alpha) * getQ(state, action) + alpha * (reward + gamma * max_value)
setQ(state, action, value)
行動の選択
行動の選択には前回と同じ$\epsilon$グリーティ手法を採用します.
# εグリーディ手法で行動選択
def greedyAction(state, epsilon):
if epsilon > np.random.rand():
action = env.action_space.sample()
else:
action = np.argmax([getQ(state, 0), getQ(state, 1), getQ(state, 2)])
return action
Qテーブルの学習
これで準備が整いました. 200ステップのエピソード(ゲーム)を10000回繰り返してQテーブルを学習します. このとき,$\epsilon=0.2$に設定しておきましょう.
env.reset() # 環境のリセット
q_table = {}
for episode in range(10000):
print("エピソード [{}]".format(episode))
observation = env.reset()
for i in range(200):
# 状態の取得
state = digitize(observation)
# εグリーディ手法で行動選択
action = greedyAction(state, 0.2)
# 次の状態に遷移
observation, reward, done, info = env.step(action)
# 次の状態
next_state = digitize(observation)
# 報酬の取得
reward = getReward((i+1), done)
# Q値の更新
updateQTable(state, action, next_state, reward)
if done:
print("Step {}".format(i+1))
break
学習したQテーブルを用いて実行しましょう. このとき,$\epsilon=0$に設定しておきましょう. うまく学習できていれば200ステップ以内に山を登り旗に到達出来るはずです.
env.reset() # 環境のリセット
observation = env.reset()
for i in range(200):
# 状態の取得
state = digitize(observation)
# εグリーディ手法で行動選択
action = greedyAction(state, 0)
# 次の状態に遷移
observation, reward, done, info = env.step(action)
print("Step {}".format(i+1))
print("状態: {}".format(observation))
print("終了判定: {}".format(done))
env.render() # 環境の描画
if done:
break