えむラボ
えむラボ
Q学習とは
Q学習 は状態$S$と行動$a$の組み合わせに対する 価値$Q(s,a)$ を学習するためのアルゴリズムです. 下記は,状態$s$で行動$a$を選択し,報酬$r$を獲得したときの更新式です. また,$Q(s’, a’)$は,状態$s$から遷移した先の状態$s’$において,行動$a’$を選択したときの価値を表しています. ここで,$\alpha$は学習率,$\gamma$は割引率と呼ばれるパラメータであり, $0 \leq \alpha \leq 1$,$0 \leq \gamma \leq 1$の範囲で設定します. 学習率は学習の収束に影響し,小さいとゆっくりと学習し,大きいと速く学習します(収束の安定性とトレードオフ). また,割引率は将来得られるであろう報酬を割り引いて評価するために用います.
$$ Q’(s,a) = (1 - \alpha)Q(s,a) + \alpha(r + \gamma \max_{a’ \in A(s’)} Q(s’, a’)) $$
| パラメータ | 意味 |
|---|---|
| $s$ | 状態 |
| $a$ | 行動 |
| $Q(s,a)$ | 状態$s$で行動$a$を選択する価値 |
| $r$ | 報酬 |
| $A(s)$ | 状態$s$で選択可能な行動の集合 |
| $\alpha$ | 学習率 |
| $\gamma$ | 割引率 |
ノートブックの作成
Jupyter Notebook を起動し,新規にノートブックを作成してください. ノートブックのタイトルは AI-12 とします. ノートブックの作成方法は第1回の資料を参照してください.
バランスゲームの復習
前回実装したバランスゲームを復習しましょう. 必要なライブラリの導入と,バランスゲーム(CartPole-v0)の初期化をします.
import gym
import numpy as np
env = gym.make('CartPole-v0') # 環境の初期化
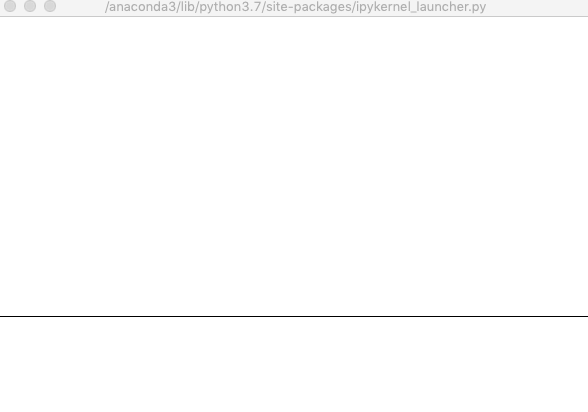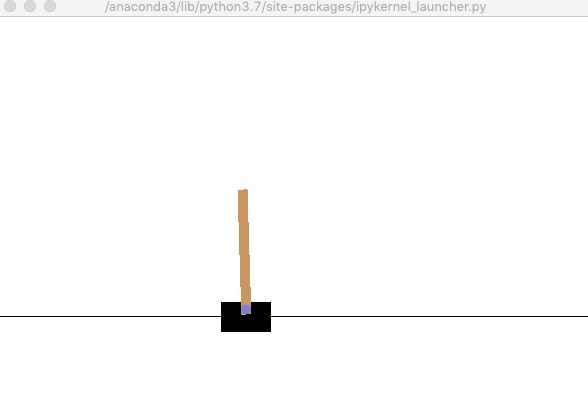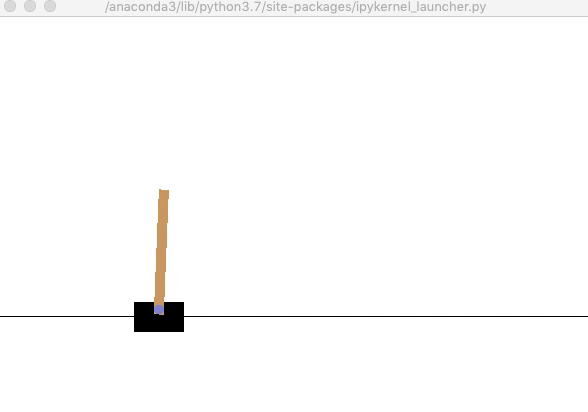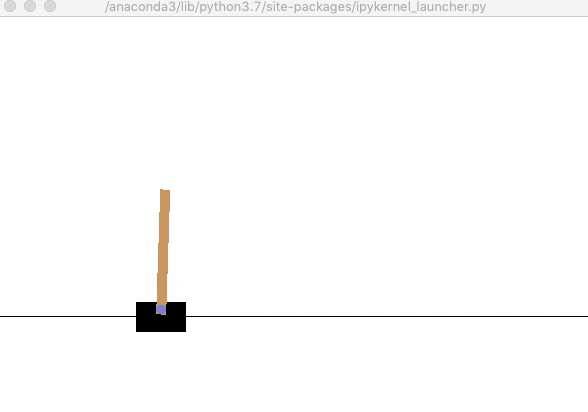
次に,200ステップに限定して,ランダムな行動選択を行なった結果を確認しましょう. ポールはあっという間に倒れてしまいます.
env.reset() # 環境のリセット
for i in range(200):
action = env.action_space.sample() # ランダムに行動選択
observation, reward, done, info = env.step(action)
print("Step {}".format(i+1))
print("状態: {}".format(observation))
print("終了判定: {}".format(done))
env.render() # 環境の描画

Q学習の実装
Qテーブルの作成
最初に 価値$Q(s,a)$ を記録しておくQテーブル(辞書型)を作成します.
また,Qテーブルに値を設定するための setQ関数,
Qテーブルから値を取得するためのgetQ関数も実装します.
q_table = {} # Qテーブル
# Q値の設定
def setQ(state, action, value):
q_table[(state, action)] = value
# Q値の取得
def getQ(state, action):
# テーブルに状態が存在しないとき
if not(state, action) in q_table:
q_table[(state, action)] = 0
return q_table[(state, action)]
状態の離散化
次に状態の離散化を行います. 本来,バランスゲームでは, カートの位置,カートの速度,ポールの角度,ポールの速度の4つの状態を 連続値 で取得します. しかし,このままではQテーブルに記録できないため,区間を定め 離散値 に変換します. 例えば,カートの位置は,-2.4〜2.4までの値をとりますが, これを6つの範囲に分割し,下記の表の離散値に変換します.
| 範囲 | 離散値 |
|---|---|
| -2.4〜-1.6 | 1 |
| -1.6〜-0.8 | 2 |
| -0.8〜0 | 3 |
| 0〜0.8 | 4 |
| 0.8〜1.6 | 5 |
| 1.6〜2.4 | 6 |
上記の変換をdigitize関数として実装します.
BIN_NUMBER = 6 # 離散値の数
# 離散値の範囲
bins = []
bins.append(np.linspace(-2.4, 2.4, BIN_NUMBER)) # カートの位置
bins.append(np.linspace(-3.0, 3.0, BIN_NUMBER)) # カートの速度
bins.append(np.linspace(-0.2, 0.2, BIN_NUMBER)) # ポールの角度
bins.append(np.linspace(-2.0, 2.0, BIN_NUMBER)) # ポールの速度
# 観測データを状態(離散値)に変換
def digitize(observation):
state = []
state.append(np.digitize(observation[0], bins[0]))
state.append(np.digitize(observation[1], bins[1]))
state.append(np.digitize(observation[2], bins[2]))
state.append(np.digitize(observation[3], bins[3]))
return tuple(state)
どのように離散値に変換されるか確認してみましょう. この例では,$(3, 3, 3, 3)$ -> $(3, 3, 3, 2)$ -> $(3, 4, 2, 2)$と状態が変化していることが確認できます.
env.reset() # 環境のリセット
for i in range(3):
action = env.action_space.sample() # ランダムに行動選択
observation, reward, done, info = env.step(action)
print(observation)
print(digitize(observation))
[-0.03864226 0.2379734 -0.0228475 -0.28297691]
(3, 3, 3, 3)
[-0.03388279 0.43341365 -0.02850703 -0.58277736]
(3, 3, 3, 2)
[-0.02521452 0.62892315 -0.04016258 -0.88430238]
(3, 4, 2, 2)
報酬と更新式
報酬をgetReward関数で定義します.
ポールが倒れていなければ$r=1$です.
一方,ポールが倒れた場合,目標ステップ(ここでは180とした)に到達していれば$r=1$,
到達していなければペナルティとして$r=-200$を与えることにします.
# 報酬の取得
def getReward(step, done):
if done:
if step >= 180:
reward = 1 # 目標ステップに到達
else:
reward = -200 # ペナルティ
else:
reward = 1
return reward
Qテーブルの更新式をupdateQTable関数で定義します.
このとき,学習率$\alpha=0.1$,割引率$\gamma=0.9$とします.
ここで,Qテーブルのキーは状態$s$と行動$a$のペアとなることに注意してください.
alpha = 0.1 # 学習率
gamma = 0.9 # 割引率
# Q値の更新
def updateQTable(state, action, next_state, reward):
max_value = max(getQ(next_state, 0), getQ(next_state, 1))
value = (1 - alpha) * getQ(state, action) + alpha * (reward + gamma * max_value)
setQ(state, action, value)
Qテーブルが更新される様子を確認してみましょう. ここでは,状態$(3, 3, 3, 3)$において,行動$1$を選択したとき, 状態$(3, 3, 3, 2)$に遷移し,報酬$1$を獲得しました. この情報を用いてQテーブルを更新すると, 状態と行動のペアの価値$Q((3, 3, 3, 3), 1)$は$0.1$に設定されたことがわかります(学習率$\alpha=0.1$だから).
env.reset() # 環境のリセット
q_table = {} #Qテーブルの初期化
# 最初の状態
action = env.action_space.sample()
observation, reward, done, info = env.step(action)
state = digitize(observation)
print("state: {}".format(state))
print("action: {}".format(action))
# 次の状態
next_action = env.action_space.sample()
observation, reward, done, info = env.step(action)
next_state = digitize(observation)
print("next_state: {}".format(next_state))
# 報酬を取得
reward = getReward(0, done)
print("reward: {}".format(reward))
# Qテーブルの更新
updateQTable(state, action, next_state, reward)
# Q値の確認
q_value = q_table[(state, action)]
print("Q value: {}".format(q_value))
state: (3, 3, 3, 3)
action: 1
next_state: (3, 3, 3, 2)
reward: 1
Q value: 0.1
行動の選択
行動の選択には$\epsilon$グリーティ手法を採用します. この手法は,確率$\epsilon$でランダムな行動を選択し, 確率$1 - \epsilon$で状態$s$において最も価値$Q(s,a)$が大きい行動$a$を選択します.
# εグリーディ手法で行動選択
def greedyAction(state, epsilon):
if epsilon > np.random.rand():
action = env.action_space.sample()
else:
action = np.argmax([getQ(state, 0), getQ(state, 1)])
return action
Qテーブルの学習
これで準備が整いました. 200ステップのエピソード(ゲーム)を1000回繰り返してQテーブルを学習します. このとき,$\epsilon=0.2$に設定しておきましょう.
env.reset() # 環境のリセット
q_table = {}
for episode in range(1000):
print("エピソード [{}]".format(episode))
observation = env.reset()
for i in range(200):
# 状態の取得
state = digitize(observation)
# εグリーディ手法で行動選択
action = greedyAction(state, 0.2)
# 次の状態に遷移
observation, reward, done, info = env.step(action)
# 次の状態
next_state = digitize(observation)
# 報酬の取得
reward = getReward((i+1), done)
# Q値の更新
updateQTable(state, action, next_state, reward)
if done:
break
学習したQテーブルを用いて実行しましょう. このとき,$\epsilon=0$に設定しておきましょう. うまく学習できていれば200ステップを維持することが出来るはずです.
env.reset() # 環境のリセット
observation = env.reset()
for i in range(200):
# 状態の取得
state = digitize(observation)
# εグリーディ手法で行動選択
action = greedyAction(state, 0)
# 次の状態に遷移
observation, reward, done, info = env.step(action)
print("Step {}".format(i+1))
print("状態: {}".format(observation))
print("終了判定: {}".format(done))
env.render() # 環境の描画