 えむラボ
えむラボ
OpenAI Gymとは
OpenAI Gymは, 機械学習の一分野である 強化学習 を開発するためのツールキットです. バランスゲーム(CartPole)や,ドライブゲーム(MountainCar)などのゲームを題材に, 強化学習のアルゴリズムを実装し評価することができます.
最初に,OpenAI Gym をインストールします. インストールしたフォルダで,PowerShellを起動し, 下記のコマンドを実行してください(Shiftキーを押しながら右クリック).
> .\Scripts\pip install gym
> .\Scripts\pip install "gym[atari]"
> .\Scripts\pip install "gym[all]"
ノートブックの作成
Jupyter Notebook を起動し,新規にノートブックを作成してください. ノートブックのタイトルは AI-11 とします. ノートブックの作成方法は第1回の資料を参照してください.
バランスゲーム(CartPole)
バランスゲームは,カートの上に垂直に立てたポールを落とさないようにバランスをとることが目的です. ユーザは,下記の状態を観測することが出来ます.
- カートの位置(-2.4 〜 2.4)
- カートの速度
- ポールの角度(-12度 〜 12度)
- ポールの速度
また,ユーザは,カートに対し,下記のいずれかの行動をとることが出来ます.
- 左に向かって力を加える(0)
- 右に向かって力を加える(1)
下記の条件を満たしたとき,ゲームは失敗となります.
- ポールが12度以上傾く
- カートの位置が画面の端に到達する(中央から2.4以上離れる)
ポールを落とさずバランスを維持して200ステップが経過すれば成功となります.
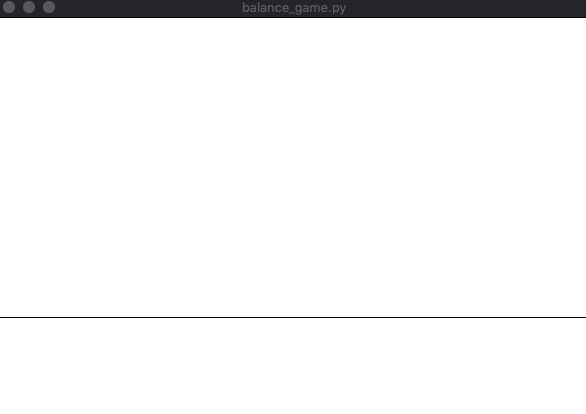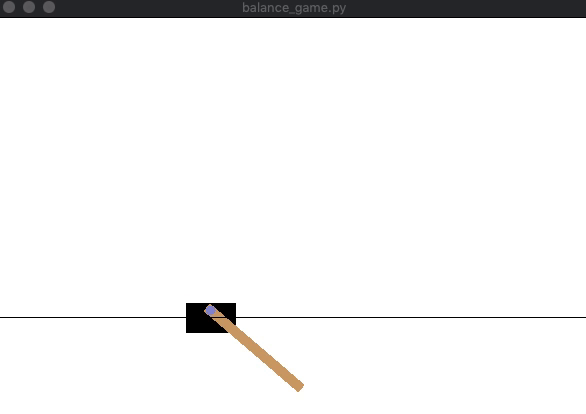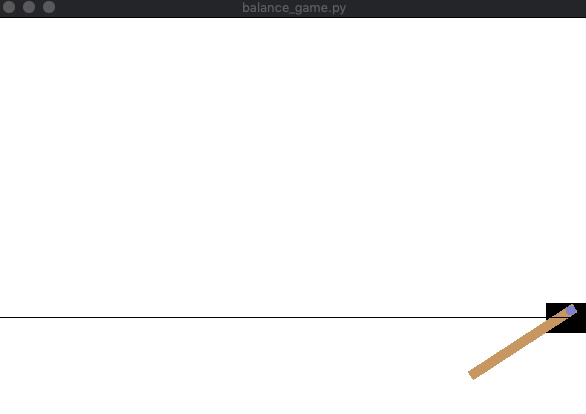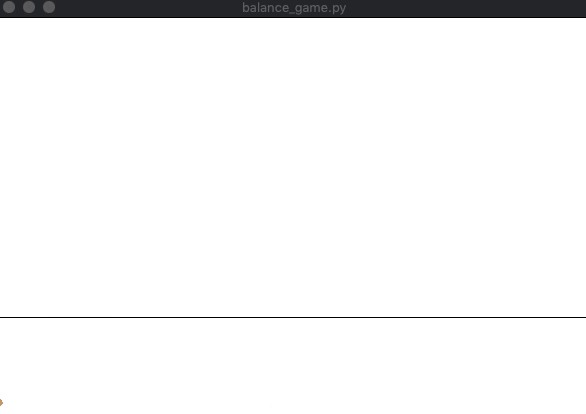
[学習前]
[学習後]
実装
今回は強化学習は利用せず,観測した状態に応じて行動を選択するアプローチで挑戦してみましょう.
まずはライブラリを導入します. ここでは,Gym に加えて,数値計算のための Numpy も導入します.
import gym
import numpy as np
最初に対象とする環境(ゲーム)を作成します. ここでは,バランスゲーム(CartPole-v0)を指定します. このゲームの 行動空間 は2種類の離散値(0:左へ押す,1:右へ押す), また,状態空間 は区間のある4種類の連続値で表されることが確認できます.
env = gym.make('CartPole-v0') # 環境の初期化
print("Action Space: {}".format(env.action_space)) # 行動空間
print("Env Space: {}".format(env.observation_space)) # 状態空間
Action Space: Discrete(2)
Env Space: Box(4,)
次に環境をreset関数で初期化します.
このとき,観測された初期状態も取得されます.
状態は4種類の要素から構成されるタプルであり,
カートの位置,カートの速度,ポールの角度,ポールの速度を表しています.
このとき,ポールの角度はラジアン角であることに注意してください.
observation = env.reset() # 環境の初期化
cart_position = observation[0] # カートの位置
cart_speed = observation[1] # カートの速度
pole_angle = observation[2] # ポールの角度
pole_speed = observation[3] # ポールの速度
print("カートの位置: {}".format(cart_position))
print("カートの速度: {}".format(cart_speed))
print("ポールの角度: {}".format(pole_angle))
print("ポールの速度: {}".format(pole_speed))
カートの位置: -0.01807530436166336
カートの速度: 0.028363315474415216
ポールの角度: -0.022288393152732122
ポールの速度: -0.010803063301248708
それでは,上記の状態をrender()関数で描画してみます.
初期状態はランダムに決定されるため,実行するごとに結果は変化します.
env.render() # 環境の描画

それでは,step関数を利用して,行動を選択します.
ここでは,「左に向かって力を加える」という行動を10回繰り返して実行しています.
この結果,カートは左に移動し,ポールが右に傾いていることがわかります.
action = 0 # 左に向かって力を加える
for i in range(10):
env.step(action)
env.render() # 環境の描画

step関数は,行動を終了後の4種類の情報を返します.
- 状態(observation)
- 報酬(reward)
- 終了判定(done)
- その他の情報(info)です.
ここでは,**状態(observation)と終了判定(done)**のみを確認してみます. ポールの角度は0.338(=19.36度)であり,これは失敗の条件を満たしています. このため,終了判定は True となっています.
observation, reward, done, info = env.step(action)
print("状態: {}".format(observation))
print("終了判定: {}".format(done))
env.render() # 環境の描画
状態: [-0.21165671 -2.12699302 0.33853234 3.51525944]
終了判定: True

では,200ステップに限定して,action_space.sample()関数を利用して,
ランダムに行動を選択してみましょう.
この結果,わずか 15ステップ でポールは倒れ失敗してしまいました.
env.reset() # 環境のリセット
for i in range(200):
action = env.action_space.sample() # ランダムに行動選択
observation, reward, done, info = env.step(action)
print("Step {}".format(i+1))
print("状態: {}".format(observation))
print("終了判定: {}".format(done))
env.render() # 環境の描画

最後に,ポールの速度 に基づき行動を選択するように改良してみましょう.
selectAction関数は,ポールの速度が右なら,右方向に力を加え,
ポールの速度が左なら,左方向に力を加えます.
この結果,先程より長く 177ステップ でカートが画面の端に到達し失敗となりました.
def selectAction(observation):
pole_speed = observation[3] # ポールの速度
if pole_speed >= 0:
action = 1 # 速度が右なら,右方向に力
else:
action = 0 # 速度が左なら,左方向に力
return action
env.reset() # 環境の初期化
for i in range(200):
action = selectAction(observation) # ポールの速度に基づき選択
observation, reward, done, info = env.step(action)
print("Step {}".format(i+1))
print("状態: {}".format(observation))
print("終了判定: {}".format(done))
env.render() # 環境の描画
