 えむラボ
えむラボ
Gymとは
Gymは, 機械学習の一分野である 強化学習 を開発するためのツールキットです. ここでは,フローズンレイク(FrozenLake)などのゲームを題材に, 強化学習のアルゴリズムを実装することができます.
ノートブックの作成
Google Colaboratory を起動し,新規にノートブックを作成してください. ノートブックのタイトルは AI-14 とします. ノートブックの作成方法は第1回の資料を参照してください.
最初に下記のライブラリも導入します.
import gym
import numpy as np
import random
import time
import matplotlib.pyplot as plt
from google.colab import output
from gym.envs.toy_text.frozen_lake import generate_random_map
フローズンレイク(FrozenLake)
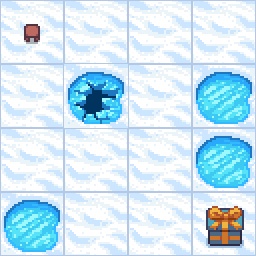
フローズンレイク(FrozenLake)は, 凍った湖の上を,湖に落ちない様に,スタート地点からゴール地点まで進むゲームです. 湖の環境は下記の画像で表現されます. 左上のプレイヤーを動かして,穴が空いた湖を避けて,右下の宝箱があるゴールに移動することを目的とします.

環境は下記のように16文字のテキストでも表現できます. ここで,Sはスタート地点,Gはゴール地点,Fは凍った湖,Hは穴が空いた湖です.
SFFF
FHFH
FFFH
HFFG
プレイヤーが観測できる情報は,プレイヤーの位置です. 事前にどこにHがあるかを知ることはできません. プレイヤーの位置は0〜15の数値で表され,Sは0,Gは15に対応します.
0 1 2 3
4 5 6 7
8 9 10 11
12 13 14 15
また,プレイヤーは,下記のいずれかの行動をとることが出来ます.
- 左に行く(0)
- 下に行く(1)
- 右に行く(2)
- 上に行く(3)
下記の条件を満たしたとき,ゲームは失敗になります.
- H に到達
下記の条件を満たしたとき,ゲームは成功になり,報酬$1$を得ます.
- G に到達
実装
環境の初期化
最初に対象とする環境を作成します.
ここでは,フローズンレイク(FrozenLake-v1)を指定します.
引数にはmap_nameとis_slipperyを設定します.
map_nameは4x4,または,8x8の2種類を指定できます.
is_slipperyはプレイヤーが氷上で滑るかどうかを表しています.
滑る(true)に設定すると,一定の確率で異なる方向に移動してしまいますが,
ここでは滑らない(false)に設定します.
このゲームの 行動 は4種類の離散値(0:左,1:下,2:右,3:上),
また,状態空間 は16種類の離散値(0〜15)であることが確認できます.
env = gym.make("FrozenLake-v1", map_name="4x4", is_slippery=False, new_step_api=True, render_mode="rgb_array") # 環境の初期化
print(env.action_space) # 行動空間
print(env.observation_space) # 状態空間
Discrete(4)
Discrete(16)
次に環境をreset関数で初期化します.
このとき,観測されたプレイヤーの位置を取得します.
プレイヤーの位置は 0(=S) であることがわかります.
ここで,env.render()はプレイヤーの環境を表す画像を生成しています.
state = env.reset() # 環境の初期化
rgb_array = env.render() # 画像を生成
plt.imshow(rgb_array[len(rgb_array)-1])
print(f"state={state}")
プレイヤーの行動
環境を初期化したら,step()を利用して,行動を選択します.
ここでは,プレイヤーを下に移動させてみます.
step()の引数に「下に行く」を表す 1(=DOWN) を指定します.
この行動の結果は下記の情報で表されます.
- プレイヤーの位置
next_state - 報酬
reward - 終了判定
done - 時間切れ
truncated(4x4は100ステップ,8x8は200ステップ) - 成功確率
info(is_slippery=Trueにすると減少)
下に移動したため,プレイヤーの位置は4になっていることがわかります.
また,報酬は0,終了状態はFalseとなっています.
報酬はプレイヤーがゴールに到達したときだけ1になります.
終了判定は穴(H)に落ちるか,ゴール(G)に到達するとTrueになります.
state = env.reset()
action = 1 # DOWN
next_state, reward, done, truncated, info = env.step(action)
rgb_array = env.render()
plt.imshow(rgb_array[len(rgb_array)-1])
print(f"next_state={next_state}")
print(f"reward={reward}")
print(f"done={done}")
print(f"info={info}")

next_state=4
reward=0.0
done=False
info={'prob': 1.0}
それでは,再度初期化してから,下(1),右(2)の順に移動してみましょう.
この結果,プレイヤーの位置は5になり,穴に落ちてしまうことがわかります.
また,終了判定はTrueになっていることも確認できます.
state = env.reset()
action = 1 # DOWN
next_state, reward, done, truncated, info = env.step(action)
action = 2 # RIGHT
next_state, reward, done, truncated, info = env.step(action)
rgb_array = env.render()
plt.imshow(rgb_array[len(rgb_array)-1])
print(f"next_state={next_state}")
print(f"reward={reward}")
print(f"done={done}")
print(f"info={info}")
next_state=5
reward=0.0
done=True
info={'prob': 1.0, 'TimeLimit.truncated': False}
ゴールに移動
実行結果の理解を簡単にするため,
下記のように辞書ACTION,関数toString()を定義しておきます.
# プレイヤーの行動
ACTION = {
0: "LEFT",
1: "DOWN",
2: "RIGHT",
3: "UP"
}
# プレイヤーの行動履歴を文字列化
def toString(histories):
moves = []
for observation, action in histories:
moves.append((observation, ACTION[action]))
return moves
それでは,ゴールに到達可能な移動を指定してみます.
ここでは,RIGHT,RIGHT,DOWN,DOWN,DOWN,RIGHTの順に移動します.
移動履歴をhistoriesに記録しておきます.
この結果,プレイヤーの位置は 15(=G),
報酬は1,終了判定がTrueになっていることがわかります.
# ゴールに到達する経路
state = env.reset()
actions = [2, 2, 1, 1, 1, 2] #RIGHT, RIGHT, DOWN, DOWN, DOWN, RIGHT
histories = []
for action in actions:
next_state, reward, done, truncated, info = env.step(action)
histories.append((state, action))
state = next_state
rgb_array = env.render()
plt.imshow(rgb_array[len(rgb_array)-1])
print(f"actions={toString(histories)}")
print(f"next_state={next_state}")
print(f"reward={reward}")
print(f"done={done}")

actions=[(0, 'RIGHT'), (1, 'RIGHT'), (2, 'DOWN'), (6, 'DOWN'), (10, 'DOWN'), (14, 'RIGHT')]
next_state=15
reward=1.0
done=True
ランダムにプレイヤーを移動
ランダムにプレイヤーを移動させてみます.
random.choice()は引数で与えられたリストからランダムに一つを選びます.
ここでは,[0, 1, 2, 3]を引数とするため,上下左右から一つが選択されます.
この結果,プレイヤーは12(=H)に到達してしまい,ゲームは失敗となります.
報酬は0,終了状態はTrueです.
state = env.reset()
histories = []
for i in range(100):
action = random.choice([0, 1, 2, 3])
next_state, reward, done, truncated, info = env.step(action)
histories.append((state, action))
state = next_state
rgb_array = env.render()
plt.imshow(rgb_array[len(rgb_array)-1])
if done:
break
print(f"actions={toString(histories)}")
print(f"next_state={next_state}")
print(f"reward={reward}")
print(f"done={done}")

actions=[(0, 'UP'), (0, 'DOWN'), (4, 'DOWN'), (8, 'DOWN')]
next_state=12
reward=0.0
done=True
マップの作成
4x4と8x8だけでなく,自由にマップを作成することができます.
# S, G, F, Hで表現
desc = [
["F", "F", "S", "F"],
["H", "F", "F", "H"],
["F", "F", "H", "F"],
["G", "F", "F", "F"]
]
env = gym.make("FrozenLake-v1", desc=desc, is_slippery=False, new_step_api=True, render_mode="rgb_array")
state = env.reset()
rgb_array = env.render()
plt.imshow(rgb_array[len(rgb_array)-1])

課題
マップを8x8に変更し,プレイヤーをゴールに到達させなさい.
Google Colaboratoryで作成した AI-14.ipynb を保存し, ノートブック(.ipynb) をダウンロードして提出しなさい. 提出の前に必ず下記の設定を行うこと.
- ノートブックの設定で「セルの出力を除外する」のチェックを外す
- ノートブックの変更内容を保存して固定