 えむラボ
えむラボ
TD学習
TD学習(Temporal Difference Learning) は,強化学習の手法の一つであり, 前回紹介した「状態$s_x$における価値$V(s_x)$」の更新式を一般化したものです.
前回の更新式を振り返りましょう. 次の式は,状態$s_x$で報酬$r$を得られたときの更新式です. この式は状態の遷移を考慮していません. このため,ランダムに状態$s_x$が選択されるときに適用します.
$$ V’(s_x) = (1 - \alpha) \cdot V(s_x) + \alpha \cdot r $$
次の式は,状態$s_x$から状態$s_y$に遷移したときの更新式です. 将来の状態$s_y$の価値を基に,現在の状態$s_x$の価値を算出しています(ブートストラップ型学習). このため,$s_x \rightarrow s_y$のように状態遷移が生じるときに適用します
$$ V’(s_x) = (1 - \alpha) \cdot V(s_x) + \alpha \cdot V(s_y) $$
一方,TD学習 は次の式で定義されます. 現在の状態$s_x$で得た報酬$r$と,将来の状態$s_y$の価値を組み合わせて, 現在の状態$s_x$の価値を算出しています. ここで,$\gamma$ は割引率と呼ばれ,将来に得られる価値を割り引いて加算するために用いられます(将来得られる価値は確実ではないため). この式は,$s_x \rightarrow s_y \rightarrow, \cdots, \rightarrow s_z$のように状態遷移が繰り返されるときに適用します.
$$ V’(s_x) = (1 - \alpha) \cdot V(s_x) + \alpha (r + \gamma \cdot V(s_y)) $$
ノートブックの作成
Google Colaboratory を起動し,新規にノートブックを作成してください. ノートブックのタイトルは AI-13 とします. ノートブックの作成方法は第1回の資料を参照してください.
ネットワーク分析のためのライブラリNetworkXをインストールします.
!pip install network
宝探しゲーム
宝探しゲームを題材に, TD学習 の振る舞いを確認します.
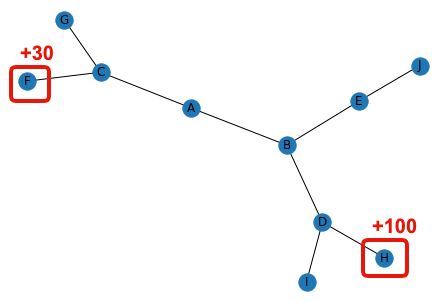
宝探しゲーム
エージェントが迷路の中で宝探しをする.
状態$s_A$からスタートし,遷移可能な状態を辿る.
エージェントは,元の状態に戻ることはせず,遷移可能な状態がなければ状態$s_A$に戻る.
状態$s_H$に到着すると報酬$+100$,状態$s_F$に到着すると報酬$+30$を獲得する.
このとき,各状態の価値(報酬の期待値)を求めよ.
実装
ネットワーク(グラフ)を分析するnetworkxと,乱数を生成するrandomをインポートします.
import networkx as nx
import random
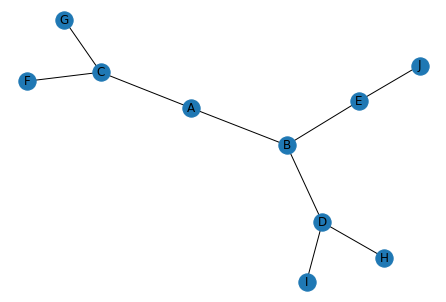
対象のネットワーク(グラフ)を作成します. ノードは状態を表し$s_A, s_B, \cdots, s_J$の10種類が存在します. エッジは遷移可能な状態を表しています. 例えば,状態$s_A$からは,$s_B$と$s_C$に遷移が可能です.
# グラフの初期化
graph = nx.Graph()
# ノード
nodes = ["A", "B", "C", "D", "E", "F", "G", "H", "I", "J"]
graph.add_nodes_from(nodes)
# エッジ
edges = [("A", "B"), ("A", "C"), ("B", "D"), ("B", "E"), ("C", "F"), ("C", "G"), ("D", "H"), ("D", "I"), ("E", "J")]
graph.add_edges_from(edges)
# 描画
nx.draw(graph, with_labels=True)
特定の状態に到達したときに得られる報酬を定義します. 状態$s_H$に到達したときに報酬$+100$,状態$s_F$に到達したときに報酬$+30$を獲得します.
# 報酬
rewards = {
"A": 0,
"B": 0,
"C": 0,
"D": 0,
"E": 0,
"F": 30,
"G": 0,
"H": 100,
"I": 0,
"J": 0
}
ノード間の状態遷移をmove()として定義します.
遷移可能な状態が複数ある場合はrandom.choice()でランダムに一つを選択します.
遷移可能な状態が存在しない$s_J$,$s_H$,$s_I$,$s_F$,$s_G$に到達した場合は,
状態$s_A$に戻ることにします.
def move(state):
# 現在の状態から選択可能なエッジ
candidates = []
for edge in edges:
if edge[0] == state:
candidates.append(edge)
if(len(candidates) == 0):
# 候補がなければ初期状態に戻る
next_state = "A"
else:
# ランダムに次の状態を選択
next_state = random.choice(candidates)[1]
# 得られる報酬
reward = rewards[state]
return (next_state, reward)
状態$s_A$をスタートとして,10回の状態遷移を繰り返してみます. この結果,次のように状態遷移を実行したことがわかります.
$$ A \rightarrow C \rightarrow G $$
$$ A \rightarrow C \rightarrow F (+30) $$
$$ A \rightarrow B \rightarrow D \rightarrow H (+100) $$
state = "A"
for i in range(10):
next_state, reward = move(state)
print(f"{state} -> {next_state} reward={reward}")
state = next_state
A -> C reward=0
C -> G reward=0
G -> A reward=0
A -> C reward=0
C -> F reward=0
F -> A reward=30
A -> B reward=0
B -> D reward=0
D -> H reward=0
H -> A reward=100
それでは,TD学習 で状態$s_x$の価値$V(s_x)$を算出してみましょう. まずは,各状態の価値を0で初期化します.
# 価値
values = {
"A": 0,
"B": 0,
"C": 0,
"D": 0,
"E": 0,
"F": 0,
"G": 0,
"H": 0,
"I": 0,
"J": 0
}
状態遷移を10,000回繰り返し,TD学習で状態$s_x$の価値$V(s_x)$を推定します. このとき,学習率は$0.01$,割引率は$0.9$に設定しています. また,価値がループして伝搬することを防ぐため, 状態$s_A$の価値$V(s_A)$は$0$とみなすことにしています.
alpha = 0.01
gamma = 0.9
state = "A"
for i in range(10000):
next_state, reward = move(state)
# 次の状態の価値
if next_state == "A":
next_value = 0
else:
next_value = values[next_state]
# TD学習
values[state] = (1 - alpha) * values[state] + alpha * (reward + gamma * next_value)
# 状態の更新
state = next_state
この結果,状態$s_x$の価値$V(s_x)$は次のように算出されました. ここで,状態の価値に応じて,遷移する状態を選択することを考えます.
- $s_A$では,$s_C=11.6$より,$s_B=18.4$の方が価値が高いため,状態$s_B$を選択
- $s_B$では,$s_E=0.0$より,$s_D=37.4$の方が価値が高いため,状態$s_D$を選択
- $s_D$では,$s_I=0.0$より,$s_H=97.0$の方が価値が高いため,状態$s_H$を選択
よって,下記の状態遷移が最適であることがわかります.
$$ A \rightarrow B \rightarrow D \rightarrow H (+100) $$
このように,TD学習で状態の価値を定めることで,エージェントの最適な方策(状態遷移の選択方法)を得ることができます.
for state in values:
print(f"state={state} value={values[state]}")
state=A value=13.988914011222555
state=B value=18.4207396271639
state=C value=11.640561941925904
state=D value=37.423600796056085
state=E value=0.0
state=F value=29.961695017091582
state=G value=0.0
state=H value=96.97275395867995
state=I value=0.0
state=J value=0.0
課題
状態$s_H$の報酬(ペナルティ)を$-100$に設定する. このとき,$V(s_x)$はどのような値になるか示せ.
Google Colaboratoryで作成した AI-13.ipynb を保存し, ノートブック(.ipynb) をダウンロードして提出しなさい. 提出の前に必ず下記の設定を行うこと.
- ノートブックの設定で「セルの出力を除外する」のチェックを外す
- ノートブックの変更内容を保存して固定