R言語によるデータの視覚化

データの可視化
データの特徴を理解するには,グラフなどを利用してデータを可視化することが重要です. R言語には散布図やヒストグラムなどで可視化するための機能がありますが, ここでは,よりリッチな可視化を実現するために,拡張パッケージのggplot2を採用します. ggplot2には,簡単に素早く描画するqplot関数と,複雑な描画が可能なggplot関数があります. 今回は,qplot関数に注目します.
スクリプトの作成
コードを入力し保存するためのスクリプトを作成しましょう. [ファイル]-[新しいスクリプト]をクリックし,Rエディタを表示します. 次に,[ファイル]-[保存]をクリックして,スクリプトを保存します. このとき,ファイル名はchapter3としてください. また,ファイルの保存場所と作業ディレクトリをデスクトップに変更しておきます.
ggplot2のインストール
まずは,ggplot2 パッケージをインストールしましょう. ツールバーから[パッケージ]-[パッケージの読み込み]をクリックし, パッケージの一覧からggplot2を選択します. これで対応するパッケージがダウンロードされます.
このパッケージを利用可能な状態にするには, library関数を利用します. ここでは,スクリプトに下記のように記述しておきます.
library(ggplot2)
これで,ggplot2 を利用する準備が整いました.
ヒストグラム
まず,ヒストグラム を描いてみましょう. 対象となるデータフレームは下記のように生成しましょう. ここで,data.frame は,引数のベクトルを列とするデータフレームを生成する関数です. また,value は列名を表しています.
y <- c(1,1,2,3,5,6,6,6,7,9)
d1 <- data.frame(value=y)
プロンプトでデータフレームd1 の要素を確認します. 要素はvalueの列だけで構成された1次元のデータとなります.
> d1
value
1 1
2 1
3 2
4 3
5 5
6 6
7 6
8 6
9 7
10 9
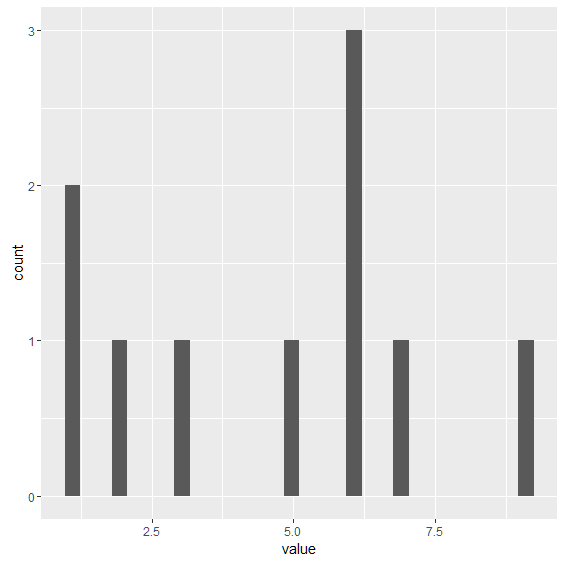
qplot() 関数を利用して,このデータフレームのヒストグラムを描きます. 引数には, Y軸の列名 , data=データフレーム名 を与えます. ここでは,下記のように value, data=d1 が引数となります.
> qplot(value,data=d1)
実行すると下記のようなヒストグラムが表示されます.
散布図
次に,散布図 を描いてみましょう. 対象となるデータフレームは下記のように生成しましょう(y は前節のベクトルを利用する). ここで,data.frame は,引数のベクトルを列とするデータフレームを生成する関数です. また,id,value は列名を表しています.
x <- c(1,2,3,4,5,6,7,8,9,10)
d2 <- data.frame(id=x,value=y)
プロンプトでデータフレームd2の要素を確認します. 要素はidとvalueのペアで構成された2次元のデータとなります.
> d2
id value
1 1 1
2 2 1
3 3 2
4 4 3
5 5 5
6 6 6
7 7 6
8 8 6
9 9 7
10 10 9
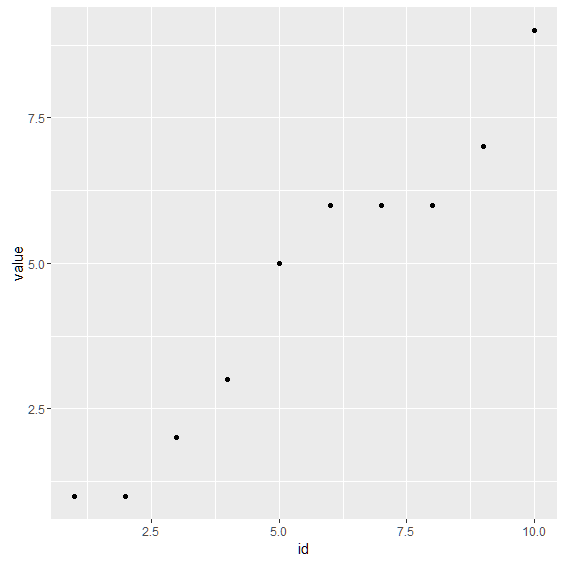
qplot() 関数を利用して,このデータフレームの散布図を描きます. 引数には,X軸の列名,Y軸の列名,data=データフレーム名 を与えます. ここでは,下記のようにid,value,data=d が引数となります.
> qplot(id,value,data=d2)
実行すると下記のような散布図が表示されます.
折れ線グラフ
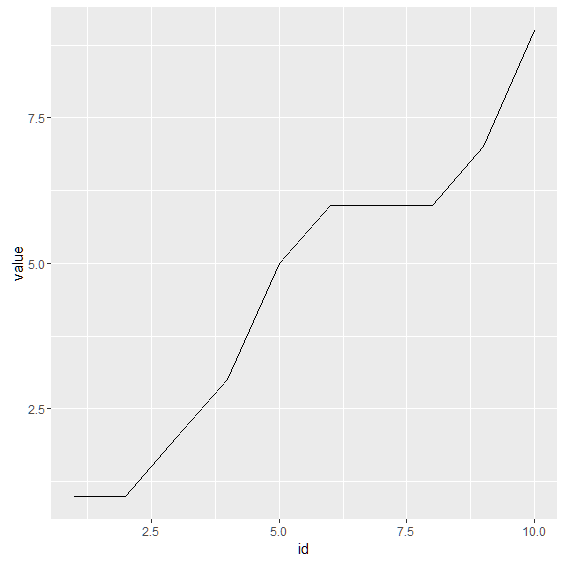
折れ線グラフを描いてみましょう. 対象となるデータは散布図と同じd2を用います. qplot() 関数には,散布図の引数に加えて geom="line” を記述します.
> qplot(id,value,data=d2,geom="line")
実行すると下記のような折れ線グラフが表示されます.
課題
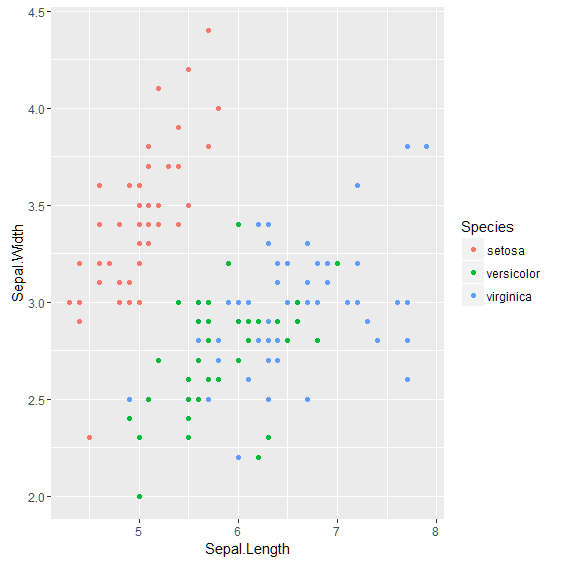
組み込みのデータフレームであるirisの Sepal.Length と Sepal.Width の2次元のデータで散布図を描いてください. このとき,引数にcolor=Speciesを加え,種類ごとに色分けすること. この アイリス(iris)は,セトナ(setosa),バーシクル(versicolor), バージニカ(virginica)という3種類のあやめのデータです. ちなみに,Sepal.Length は がく片長 ,Sepal.Width は がく片幅を意味しています. ソースはchapter3.Rに記述し,コンソールの出力結果,グラフ(散布図)の画像ファイル,chapter3.R を提出すること.