深層学習のデータセット

データセットの紹介
TorchvisionにはCIFAR-10以外にも様々なデータセットが用意されています. ここでは,MNIST ,Fashion-MNIST ,KMNIST ,COCO , Cityscapes を取り上げて紹介します.
import torchvision
import matplotlib.pyplot as plt
MNIST
MNISTは 手書きの数字文字 のデータセットです. グレースケール画像で,サイズは$28 \times 28$です.
dataset = torchvision.datasets.MNIST(root="./data", download=True)
image, label = dataset[0]
print(label)
plt.imshow(image, cmap="gray")
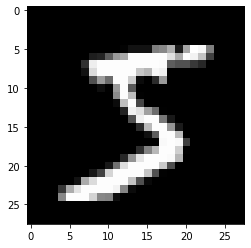
Fashion-MNIST
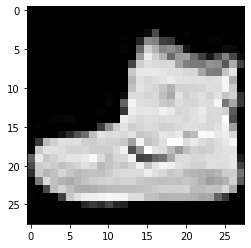
Fashion-MNISTは 衣服などの ファッション のデータセットです. グレースケール画像で,サイズは$28 \times 28$です.
dataset = torchvision.datasets.FashionMNIST(root="./data", download=True)
image, label = dataset[0]
print(label)
plt.imshow(image, cmap="gray")
KMNIST
KMNISTは くずし字(ひらがなや漢字) のデータセットです. グレースケール画像で,サイズは$28 \times 28$です.
dataset = torchvision.datasets.KMNIST(root="./data", download=True)
image, label = dataset[0]
print(label)
plt.imshow(image, cmap="gray")
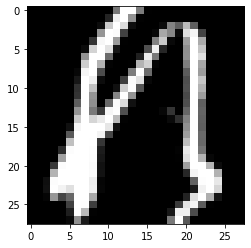
EMNIST
EMNISTは,手書きアルファベット のデータセットです(spolit="letters"を指定).
ラベル1がA,ラベル26がZを表します(0から始まらないことに注意).
グレースケール画像で,サイズは$28 \times 28$です.
dataset = torchvision.datasets.EMNIST(root="./data", split="letters", download=True)
image, label = dataset[0]
print(label)
plt.imshow(image, cmap="gray")

COCO
COCOは物体検出やセグメンテーションなどに利用されるデータセットです. 33万枚以上の画像で構成され,80種類のラベルが存在します. 画像のアノテーションはJSON形式で配布されています.
Cityscapes
Cityscapesは,人や車両のセグメンテーションなどに利用されるデータセットです. 50の市街における5000枚の高精度なアノテーション付きの画像と,20000枚の粗いアノテーション付きの画像が提供されます.
課題
Google Colaboratoryで,任意のデータセットを, 畳み込みニューラルネットワークで学習し,学習データに対する正解率を算出してください. 下記はMNISTの手書き数字文字のデータセットの例です(「0」,「1」,「2」の3種類のみを対象).
# データセットの読込(Tensor)
dataset = torchvision.datasets.MNIST(root="./data", transform=transforms.ToTensor())
# 0,1,2のみを対象とする
my_dataset = []
for image, label in dataset:
if label == 0 or label == 1 or label == 2:
my_dataset.append((image, label))
手書き数字画像はグレースケール(1次元)であり,そのサイズは$28 \times 28$であることに注意してください. 畳み込みニューラルネットワークは次のように定義すると良いです(最初の畳み込み層の入力チャネルが$1$,全結合層の入力数は$16 \times 4 \times 4=256$).
# 画像はグレースケール(1次元)
# 画像サイズ 28x28 -> 24x24 ->12x12 -> 8x8 -> 4x4
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, (5, 5)) #入力チャネル,出力チャネル,フィルタサイズ
self.conv2 = nn.Conv2d(6, 16, (5, 5)) #入力チャネル,出力チャネル,フィルタサイズ
self.fc1 = nn.Linear(16 * 4 * 4, 64) #入力数,出力数
self.fc2 = nn.Linear(64, 3) #入力数,出力数
def forward(self, x):
x = F.max_pool2d(F.relu(self.conv1(x)), 2) #2x2でMAXプーリング
x = F.max_pool2d(F.relu(self.conv2(x)), 2) #2x2でMAXプーリング
x = x.view(-1, 16 * 4 * 4) #1次元に整形
x = F.relu(self.fc1(x))
x = F.softmax(self.fc2(x), dim=1)
return x
network = Net()
print(network)
ノートブックのタイトルをchapter7.ipynb として保存し, 共有用のリンク と ノートブック(.ipynb) をダウンロードして提出してください. 提出の前に必ず下記の設定を行ってください.
- ノートブックの設定で「セルの出力を除外する」のチェックを外す
- ノートブックの変更内容を保存して固定
- 共有設定で「学校法人椙山女学園大学」を「閲覧者」に設定